在这系列的博文中,我将描述从开发到部署再到监控的整个机器学习服务开发过程。这是MLOps zoomcamp课程的最终项目。
本系列旨在训练一个简单的情感分析模型,并将其部署到Google Cloud(Cloud Run)作为无服务器微服务,使用Streamlit构建简单的用户界面,并利用MLflow、Prefect&ZenML以及EvidentlyAI&Seldon ALIBI Detect等MLOps工具进行实验跟踪、工作流编排和模型监测。
该程序接收一条电子商务服装评论,并预测客户是否会向她的朋友推荐该产品。你可以在这里找到数据集。
根据您提供的文章片段,翻译如下:
我们在这里并不过多关注模型的开发。我以一个Kaggle笔记本为参考,并将尝试使用MLflow进行实验跟踪。您可以查看主要的笔记本来获取进一步的数据预处理和可视化信息。
那么,什么是实验跟踪呢?实验跟踪是记录机器学习实验中所有相关信息的过程,其中包括:
- 源代码
- 环境
- 数据
- 模型
- 超参数
- 指标
- …
实验跟踪为何重要? • 可重现性: • 组织性 • 优化性 MLflow是一个开源平台,用于管理端到端的机器学习生命周期,并且我们将在这里使用它。它涵盖了四个主要功能:[来源]
实验跟踪对于机器学习项目非常重要。以下是它的重要性原因: 1. 可重现性:通过实验跟踪,我们可以记录所有与实验相关的信息,例如代码、数据、超参数等。这确保了实验的可重现性,其他人可以在相同的条件下重现实验,验证和复现结果。 2. 组织性:实验跟踪有助于组织和管理机器学习项目。您可以准确跟踪每个实验的详细信息,包括使用的数据集、训练算法、评估指标等。这样可以更好地组织实验结果,比较不同实验的效果,并更好地了解实验之间的差异。 3. 优化性:实验跟踪通过记录实验中的信息和指标,帮助我们优化模型。通过分析实验结果和指标,我们可以确定最佳的超参数、数据处理方法和模型架构,从而提高模型的性能和效果。
跟踪实验以记录和比较参数和结果(MLflow Tracking)。MLflow Tracking组件是一个API和用户界面,用于在运行机器学习代码时记录参数、代码版本、指标和输出文件,以便后续对结果进行可视化。
将ML代码以可重用、可复现的形式打包,以便与其他数据科学家共享或转移到生产环境中(MLflow Projects)。
从各种ML库管理和部署模型到各种模型服务和推断平台(MLflow Models)。
提供一个中央模型存储库,用于协作管理完整的MLflow模型生命周期,包括模型版本控制、阶段转换和注释(MLflow Model Registry)。
您可以通过阅读MLflow的文档,并观看MLOps Zoomcamp课程的视频,进一步了解MLflow。
在这篇文章中,我们针对情感分析任务训练了三种不同的机器学习模型:词袋模型(Bag of Words)、TF-IDF模型和一个简单的神经网络模型。
首先,您需要使用pip安装MLflow。您可以在此处了解更多信息。
然后,您可以使用以下命令来运行MLflow用户界面(UI):
mlflow ui - backend-store-uri sqlite:///mlflow.db
还可以在云上运行MLflow来存储模型和元数据。我写了一篇关于如何在Google Cloud Platform(GCP)上设置MLflow的博客文章,您可以在这里阅读。
对于超参数优化,您可以使用hyperopt库。目前,hyperopt实现了三种算法:
- 随机搜索(Random Search)
- Parzen估计树(TPE,Tree of Parzen Estimators)
- 自适应TPE(Adaptive TPE)
Hyperopt专为基于高斯过程和回归树的贝叶斯优化算法设计,但目前尚未实现这些算法。
在我们的情况下,参数不是很多,所以我们不使用hyperopt,但您可以了解一下它。 我们先从词袋模型(BoW model)开始:
import numpy as np
import pandas as pd
import os
import re
os.environ["NLTK_DATA"] = "./corpora"
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer as CV
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import accuracy_score
import pickle
import mlflow
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("customer-sentiment-analysis")
## data loading
data = pd.read_csv('Womens Clothing E-Commerce Reviews.csv',index_col =[0])
## preprocess text
data = data[~data['Review Text'].isnull()] #Dropping columns which don't have any review
X = data[['Review Text']]
X.index = np.arange(len(X))
y = data['Recommended IND']
corpus =[]
for i in range(len(X)):
review = re.sub('[^a-zA-z]',' ',X['Review Text'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review =[ps.stem(i) for i in review if not i in set(stopwords.words('english'))]
review =' '.join(review)
corpus.append(review)
cv = CV(max_features = 3000,ngram_range=(1,1))
X_cv = cv.fit_transform(corpus).toarray()
y = y.values
X_train, X_test, y_train, y_test = train_test_split(X_cv, y, test_size = 0.20, random_state = 0)
mlflow.sklearn.autolog()
with mlflow.start_run():
mlflow.set_tag("developer", "Isaac")
mlflow.set_tag("algorithm", "BernoulliNB")
mlflow.log_param("train-data", "Womens Clothing E-Commerce Reviews")
alpha = 1
mlflow.log_param("alpha", alpha)
classifier = BernoulliNB(alpha = alpha)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
acc = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", acc)
print("accuracy on test data:", acc)
model_name = "model_bow.bin"
with open("models/" + model_name, 'wb') as fout:
pickle.dump((cv, classifier), fout)
mlflow.log_artifact(local_path="models/" + model_name, artifact_path="models_pickle")
您可以看到使用MLflow来跟踪机器学习模型开发过程是多么简单。
我们也可以为TF-IDF模型进行同样的过程:
import numpy as np
import pandas as pd
import os
import nltk
import re
# nltk.download('stopwords')
os.environ["NLTK_DATA"] = "./corpora"
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
from sklearn.feature_extraction.text import TfidfVectorizer as TV
import pickle
import mlflow
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("customer-sentiment-analysis")
## data loading
data = pd.read_csv('Womens Clothing E-Commerce Reviews.csv',index_col =[0])
## preprocess text
data = data[~data['Review Text'].isnull()] #Dropping columns which don't have any review
X = data[['Review Text']]
X.index = np.arange(len(X))
y = data['Recommended IND']
corpus =[]
for i in range(len(X)):
review = re.sub('[^a-zA-z]',' ',X['Review Text'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review =[ps.stem(i) for i in review if not i in set(stopwords.words('english'))]
review =' '.join(review)
corpus.append(review)
tv = TV(ngram_range =(1,1),max_features = 3000)
X_tv = tv.fit_transform(corpus).toarray()
X_train, X_test, y_train, y_test = train_test_split(X_tv, y, test_size = 0.20, random_state = 0)
mlflow.sklearn.autolog()
with mlflow.start_run():
mlflow.set_tag("developer", "Isaac")
mlflow.set_tag("algorithm", "MultinomialNB")
mlflow.log_param("train-data", "Womens Clothing E-Commerce Reviews")
alpha = 1
mlflow.log_param("alpha", alpha)
classifier = MultinomialNB(alpha = alpha)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
acc = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", acc)
print("accuracy on test data:", acc)
model_name = "model_tfidf.bin"
with open("models/" + model_name, 'wb') as fout:
pickle.dump((tv, classifier), fout)
mlflow.log_artifact(local_path="models/" + model_name, artifact_path="models_pickle")
最后是深度学习模型:
import numpy as np
import pandas as pd
import os
import nltk
import re
# nltk.download('stopwords')
os.environ["NLTK_DATA"] = "./corpora"
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import mlflow
import pickle
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("customer-sentiment-analysis")
## data loading
data = pd.read_csv('Womens Clothing E-Commerce Reviews.csv',index_col =[0])
## preprocess text
data = data[~data['Review Text'].isnull()] #Dropping columns which don't have any review
X = data[['Review Text']]
X.index = np.arange(len(X))
y = data['Recommended IND']
corpus =[]
for i in range(len(X)):
review = re.sub('[^a-zA-z]',' ',X['Review Text'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review =[ps.stem(i) for i in review if not i in set(stopwords.words('english'))]
review =' '.join(review)
corpus.append(review)
## tokenization and dataset creation
tokenizer = Tokenizer(num_words = 3000)
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
padded = pad_sequences(sequences, padding='post')
X_train, X_test, y_train, y_test = train_test_split(padded, y, test_size = 0.20, random_state = 0)
with mlflow.start_run():
## model definition
embedding_dim = 32
model = tf.keras.Sequential([
tf.keras.layers.Embedding(3000, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
## training
num_epochs = 50
batch_size = 32
callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
min_delta=0,
patience=2,
verbose=0,
mode="auto",
baseline=None,
restore_best_weights=False,
)
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
mlflow.set_tag("developer", "Isaac")
mlflow.set_tag("algorithm", "Deep Learning")
mlflow.log_param("train-data", "Womens Clothing E-Commerce Reviews")
mlflow.log_param("embedding-dim", embedding_dim)
print("Fit model on training data")
history = model.fit(
X_train,
y_train,
batch_size=batch_size,
epochs=num_epochs,
callbacks=callback,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(X_test, y_test),
)
## save model and tokenizer
mlflow.keras.log_model(model, 'models/model_dl')
with open('models/tf_tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
mlflow.log_artifact(local_path="models/tf_tokenizer.pickle", artifact_path="tokenizer_pickle")
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(X_test, y_test, batch_size=128)
print("test loss, test acc:", results)
mlflow.log_metric("loss", results[0])
mlflow.log_metric("accuracy", results[1])
正如您所见,我们可以使用autolog()函数来自动记录TensorFlow和Scikit Learn的参数,或者我们也可以手动记录我们想要的任何内容。最后,在使用不同的超参数训练不同模型后,您将看到类似下面的结果:
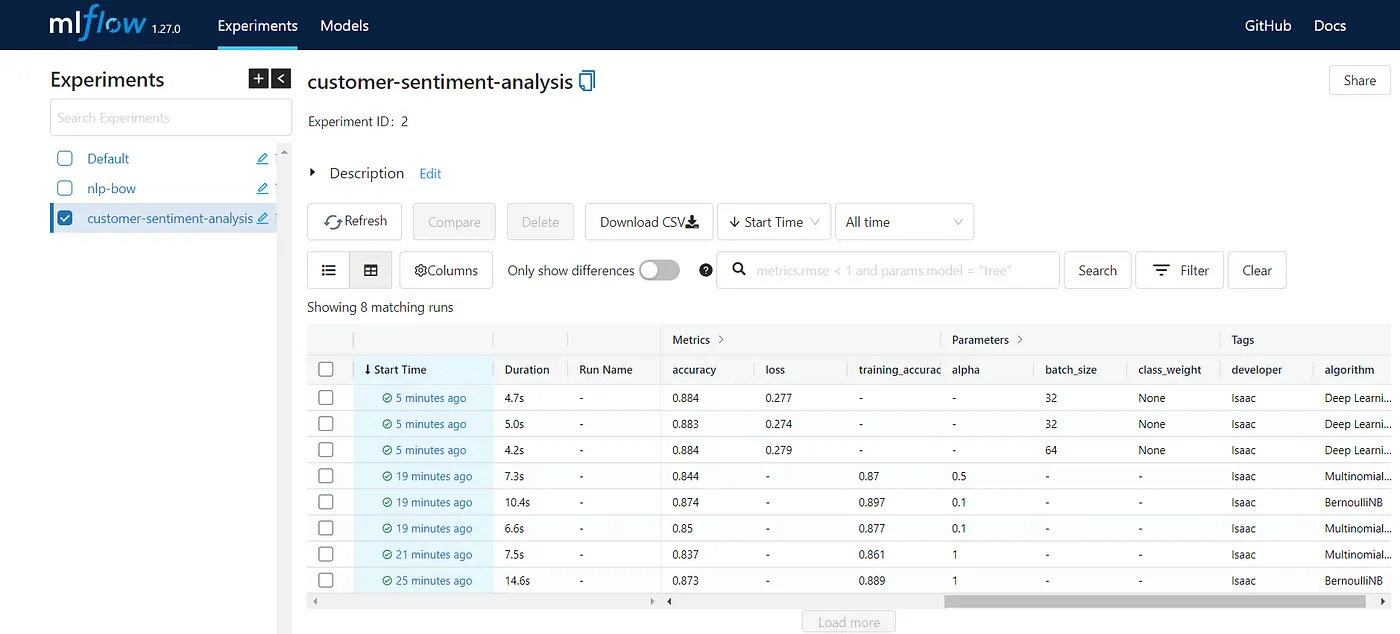
然后,您可以轻松地访问每个实验并查看每次运行的更多细节,并进行比较。您可以根据训练时间、准确性等不同参数选择一个模型。
请注意,我们可以使用以下两种方式之一记录模型:
基于框架保存模型,然后使用
mlflow.log_artifact(local_path=<保存模型的本地路径>,artifact_path=<要将模型保存在mlruns中的文件夹名称>)进行记录。在上面的深度学习版本中,我们使用了这种方法来保存分词器(tokenizer)。另外,您还可以使用
mlflow.<framework>.log_model(…)。在上面的深度学习版本中,我们使用了这种方法来保存Keras模型。
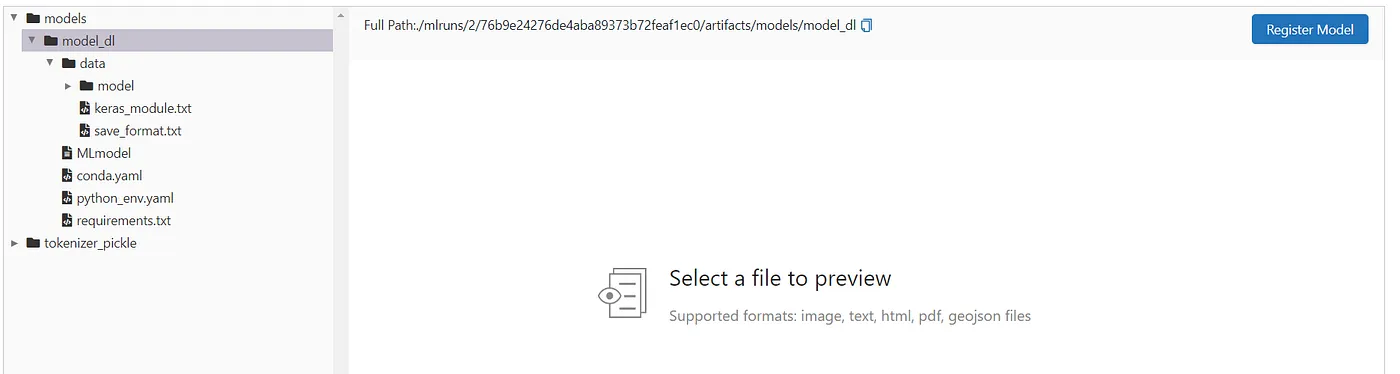
让我们来看一下其中一次运行保存了哪些内容。例如,我们来看一下深度学习模型的一次运行的结果:
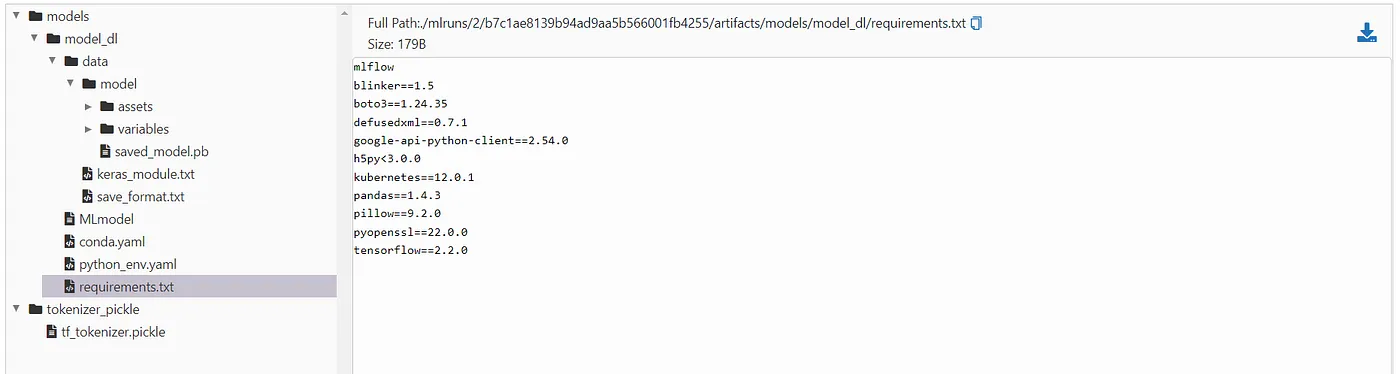
正如您所见,模型、分词器以及所有所需Python包的信息和其他元数据都被保存了下来。每个运行都有一个唯一的运行ID,我们稍后会用到它。
现在,让我们进入下一个阶段,称为模型管理,这一阶段介绍如何管理已训练的模型。
正如您从上面的代码中看到的,我们对每次运行保存了模型。接下来应该进行模型版本管理,然后进行部署。让我们看看MLflow如何用于模型管理。
在之前的步骤中,我们将拥有多个模型运行和训练模型。数据科学家随后必须根据多个指标选择其中一部分模型,并将其注册到MLflow模型注册表中。模型注册表包括多个阶段/标签,包括暂存(staging)、生产(production)和归档(archive)。模型首先进入暂存阶段。MLflow模型注册表是一个集中化的模型存储库,具有用于管理整个MLflow模型生命周期的API和用户界面。它包括模型血统(记录了创建模型的MLflow实验和运行)、模型版本控制、阶段转换(例如从暂存转到生产阶段)和注释[ 来源 ]。
然后,部署工程师或团队可以开始使用模型注册表中的模型和暂存模型,并根据模型的大小或推理时间等参数,决定哪个模型将进入生产阶段。
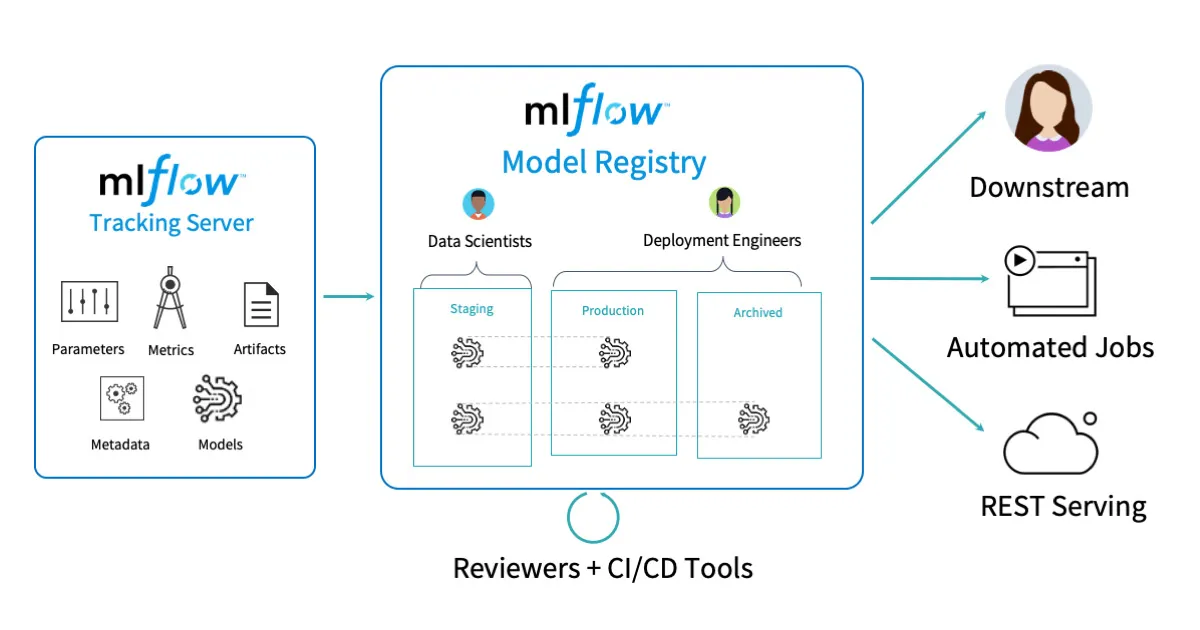
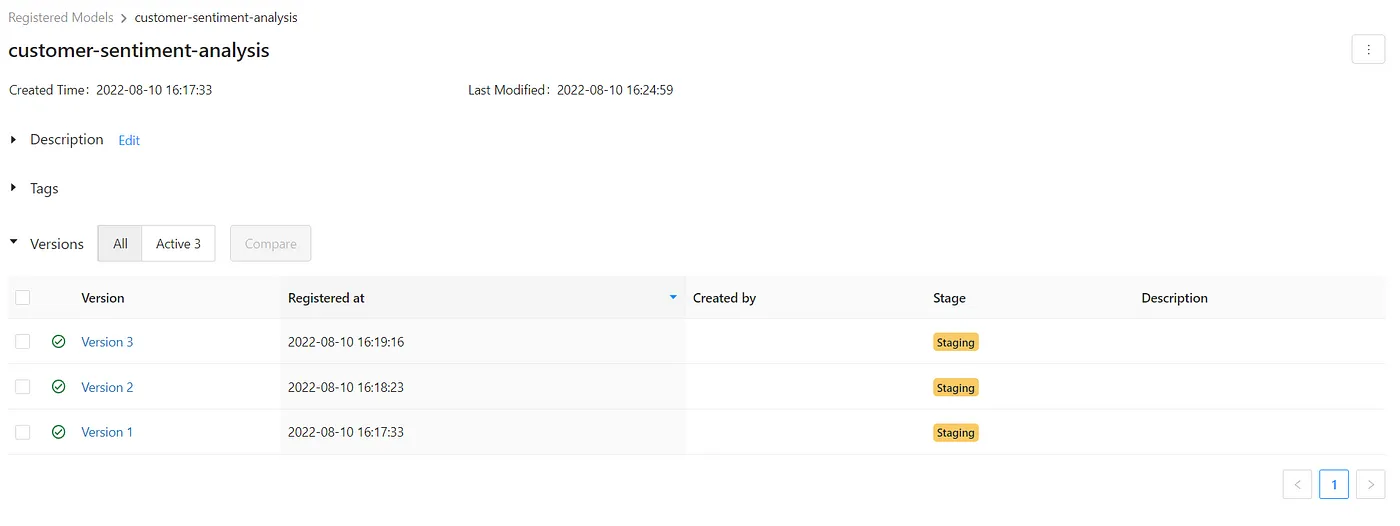
要在模型注册表中注册一个模型,请选择其中一个运行,并在Artifacts下选择模型文件夹。然后,”Register Model“按钮将变为可见状态。您必须选择一个包含所有版本的模型名称。我们创建了一个模型名称为”customer-sentiment-analysis”,并根据准确性指标注册了三个模型,每个方法一个。
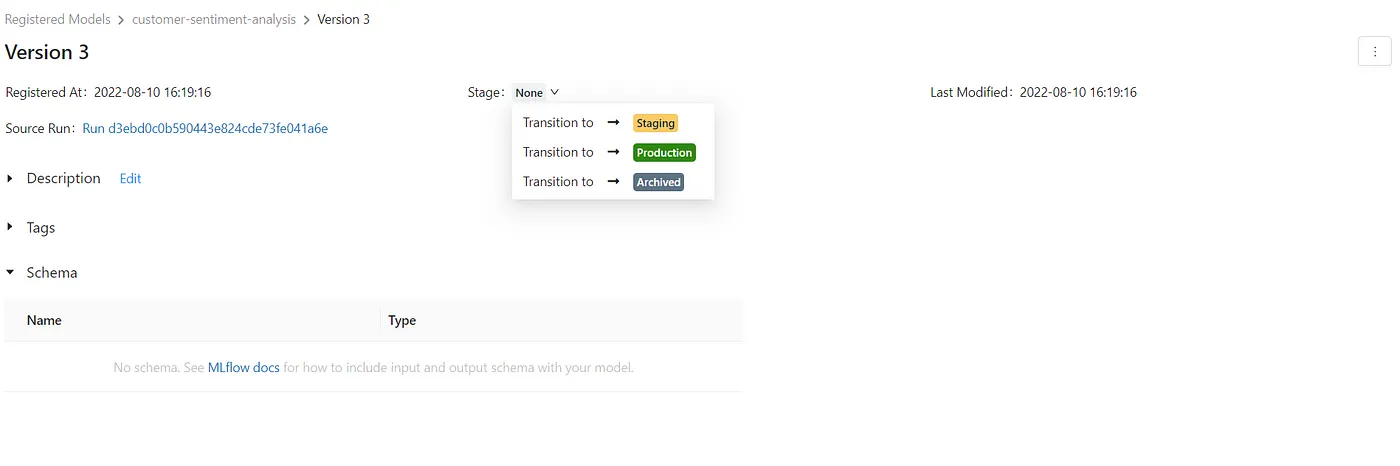
接下来,如果您转到屏幕上方的”Models“选项卡,您将看到所有的版本。您可以选择每个版本,然后设置其阶段。在这里,我们将所有版本都设置为暂存状态。增加对每个版本更改的数据描述以及开发人员的姓名是一个很好的做法。
您还可以使用API和MlflowClient,在代码中执行这些步骤。请在这里查看API文档,并通过以下视频了解更多细节。我更推荐使用用户界面。
然后,您可以比较处于暂存阶段的模型,并选择一个用于生产部署。在我们的例子中,深度学习模型的准确性更高,因此我们将其推进到生产阶段。当您将模型转换至生产阶段时,模型注册表仅为该模型版本分配一个标签,实际上并未将模型部署到生产环境中。可以借助具体的部署代码完成实际的部署,来为注册表增添连续集成与持续交付(CI/CD)的流程。
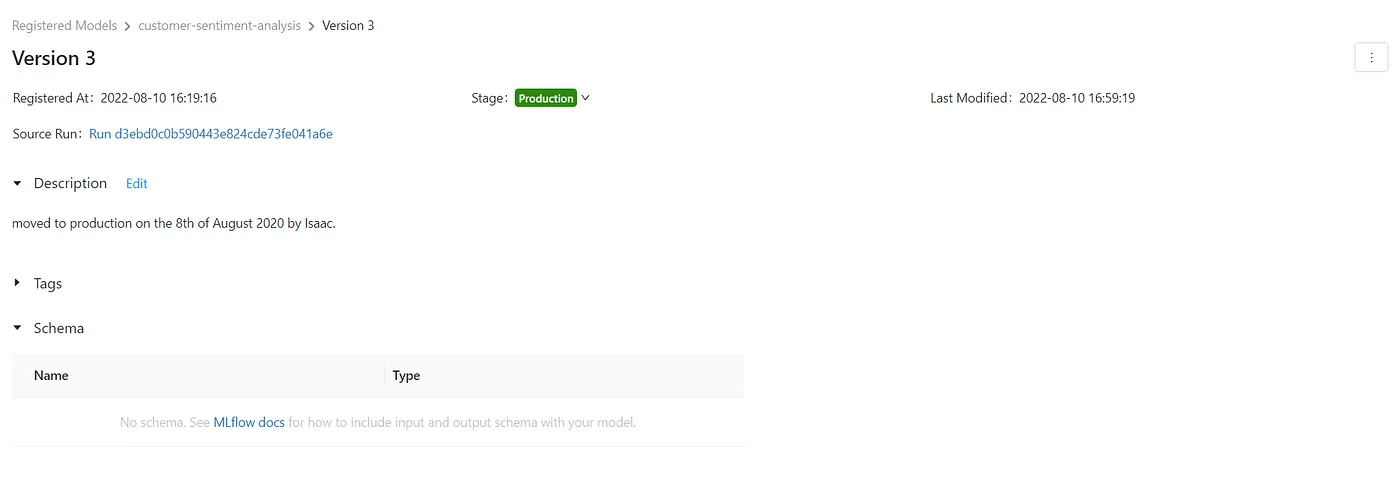
然后,我们可以使用该版本的运行ID下载模型及其他所需文件,如分词器,并进行部署。在我们的案例中,我们希望加载Keras模型。请查看文档以获取更多详细信息:
mlflow.keras.load_model(model_uri, dst_path=None)
在models:/<model_name>/<stage or version>中,<model_name>代表模型名称,而 <stage or version> 表示阶段或版本。在您的例子中,模型名称是customer-sentiment-analysis,阶段为production。
import mlflow
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("customer-sentiment-analysis")
mlflow.keras.load_model("models:/customer-sentiment-analysis/production", dst_path=None)
or
mlflow.keras.load_model("models:/customer-sentiment-analysis/3", dst_path=None)
如果您想将模型保存到本地,您可以设置dst_path参数。同时,我们也可以下载分词器:
from mlflow.tracking import MlflowClient
client = MlflowClient(tracking_uri="sqlite:///mlflow.db")
client.download_artifacts(run_id="d3ebd0c0b590443e824cde73fe041a6e", path='tokenizer', dst_path='.')
其中,run_id是生产模型的运行ID,您可以从MLFlow的用户界面获取。
我们还可以从Google Storage或Amazon S3中读取模型和相关文件。请查看文档以获取更多详细信息。
您可以查看以下视频和我的博文,了解如何在AWS或GCP上设置MLflow。
在接下来的博文中,我们将更多地了解如何在生产阶段使用模型。这就是第一篇博文的内容。下一篇博文将介绍编排。
感谢您抽出时间阅读我的博文。如果您觉得有帮助或愉快,请考虑点赞并与您的朋友分享。您的支持对我来说意义重大,也帮助我继续为您创造有价值的内容。
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2023/08/31/mlops-project-part-1-machine-learning-experiment-tracking-using-mlflow/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)