原文:MLOps project — part 2a: Machine Learning Workflow Orchestration using Prefect
在上一篇博文中,我们学习了如何使用MLflow训练模型并跟踪实验。
在本系列的第二篇文章中,我们将把上一阶段的代码转换为一个机器学习流水线。我将演示如何使用两个流行的工具进行任务完成:Prefect和ZenML。还有一些令人难以置信的工具,我们无法在本文中全部包含,比如Flyte、Kale、Aro等。
在这篇文章中,我们将从Prefect开始,下一篇文章将介绍ZenML。 但是为什么我们的机器学习服务需要一个流水线?ZenML手册中有详细的描述 [来源]:
作为机器学习从业者,您可能熟悉使用Scikit-learn、PyTorch、TensorFlow或类似工具构建机器学习模型。机器学习流水线只是一个扩展,包括通常在构建模型之前或之后进行的其他步骤,例如数据获取、预处理、模型部署或监控。机器学习流水线基本上定义了您作为机器学习从业者工作的逐步过程。通过以代码方式明确定义机器学习流水线具有以下优势:
- 我们可以轻松重新运行所有工作,而不仅仅是模型,消除错误并使我们的模型更易于复现。
- 数据和模型可以进行版本控制和跟踪,因此我们可以一目了然地看到模型是在哪个数据集上训练的,以及与其他模型相比如何。
- 如果整个流水线都编码完成,我们可以自动化许多运营任务,比如在底层问题或数据改变时重新训练和重新部署模型,或者使用CI/CD工作流推出新的改进模型。
在构建模型时,我们可能有一系列的预处理步骤,在每次训练模型时不希望重复执行,比如在上一篇博文中生成corpus列表的步骤。 我们可能还需要比较不同模型的性能,或者希望部署模型并监控数据和模型性能。在这种情况下,机器学习流水线发挥作用,允许我们将工作流程指定为一系列可组合的模块化步骤。
此外,我们可能有一个每周执行的机器学习流水线。我们可以将其安排在时间表上,如果机器学习模型失败或输入数据有问题,我们可以分析和解决这些问题。
让我们考虑一个标准的机器学习流水线:
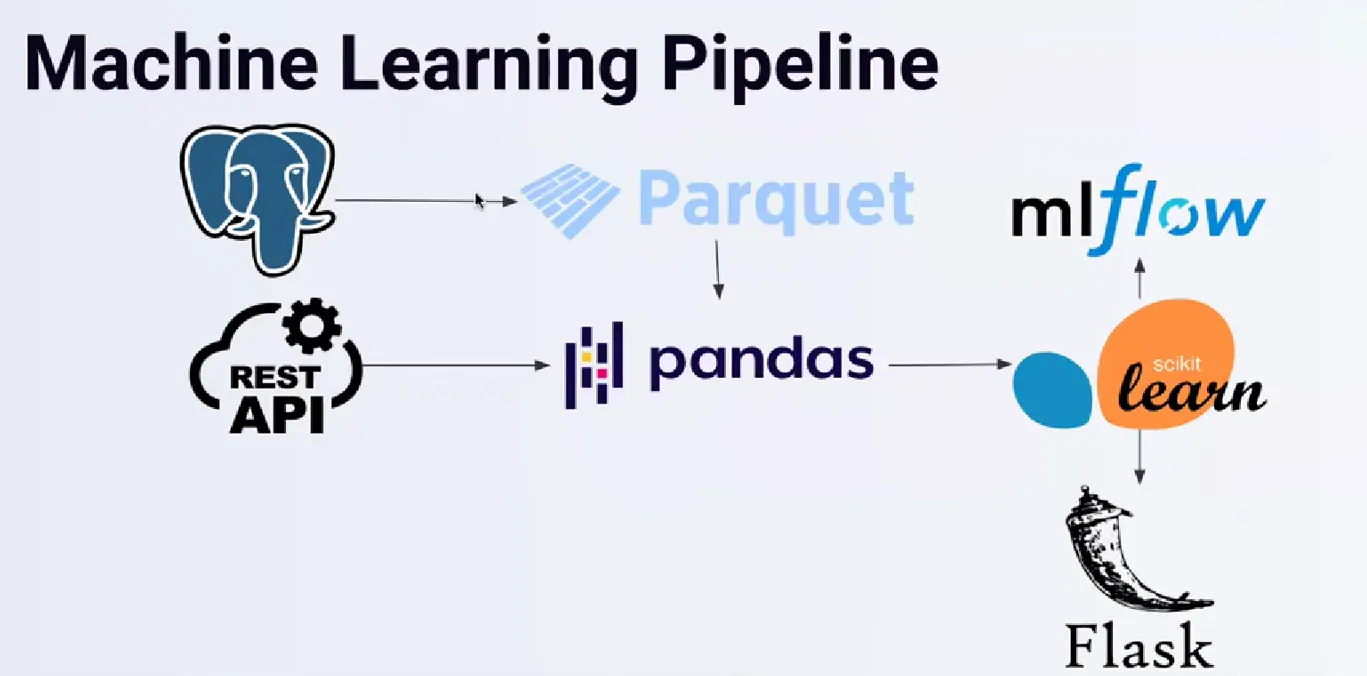
在开始阶段,我们拥有一个PostgreSQL数据库,可能还有一个将数据写入Parquet文件的过程。接下来,我们使用pandas读取Parquet文件,并将其与我们提取的API数据合并。
在训练模型之后,我们使用MLflow注册产物并进行实验;如果满足特定条件,我们可能会使用Flask等工具部署模型。
显然,这些阶段是相互关联的;如果其中一个阶段失败,整个流水线都会受到影响。
失败可能以意想不到的方式发生。例如,输入数据存在缺陷,API在某些时刻无法连接,MLflow也可能出现类似情况。如果您使用数据库存储MLflow的产物或实验等,问题可能会出现。工作流编排旨在减轻这些问题的影响,并协助解决这些问题。
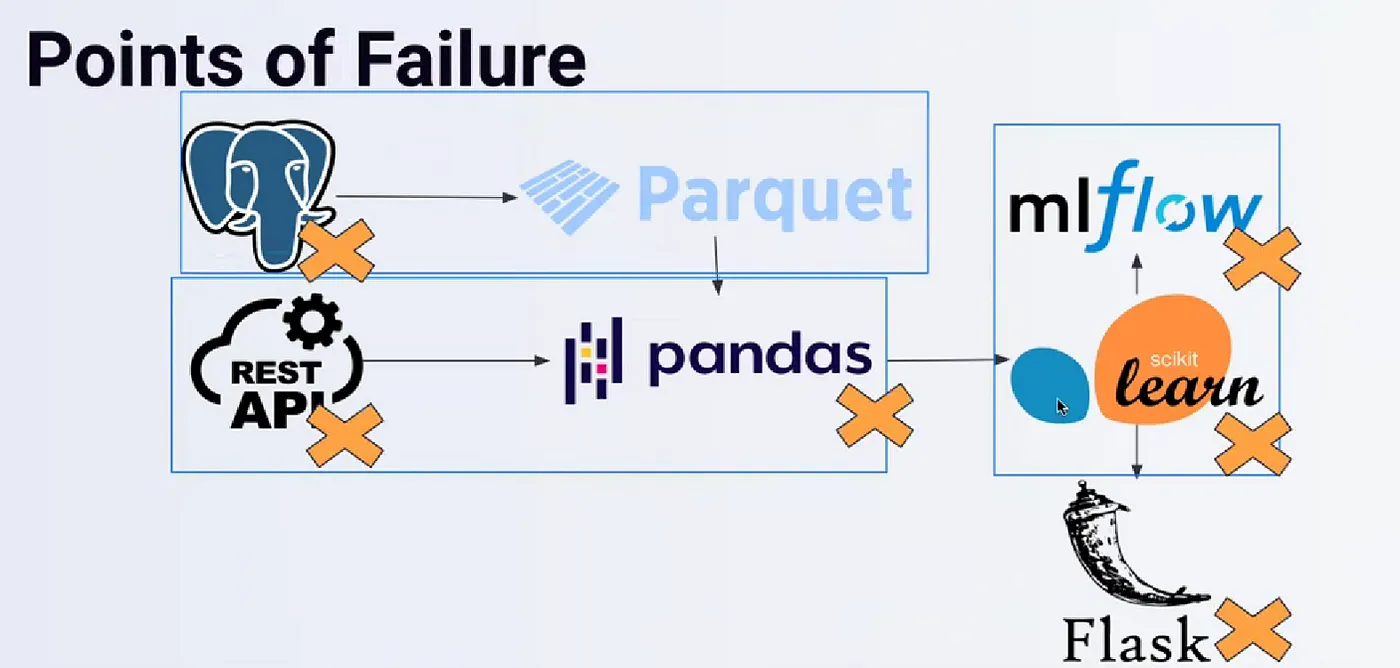
所有这些都将帮助组织和开发人员更快地完成任务并找到问题,使他们能够将注意力集中在更重要的事情上。 太好了!让我们看看如何在实践中完成。我们的流水线可能如下所示:

对于这个项目,我们实际上并不需要流水线,但我只是想展示一下我们如何创建一个流水线。根据使用情况,拥有一个流水线可能会很有用。例如,如果您有一个要定期执行的数据流水线,或者想要一个用于训练机器学习模型的流水线。在这里,我只是想展示如果您在项目中需要,可以如何做到这一点。
让我们看看Prefect如何帮助我们。
Prefect
Prefect是一个现代数据堆栈的工具,帮助您监控、协调和编排应用程序之间以及跨应用程序之间的数据流。您可以构建流水线,在任何地方部署它们,并进行远程配置。如果您在处理数据,可能需要以下功能 [来源]:
- 定时任务
- 重试机制
- 日志记录
- 缓存
- 通知
- 可观测性
在您的数据流中实现所有这些功能是一项繁重的工作,需要大量时间,而这些时间本应更好地用于编写功能代码。
Prefect 2.0 提供了所有这些功能以及更多!
您可以使用以下命令轻松安装Prefect:
pip install prefect
我安装了Prefect 2.0.4 版本。我发现API变化很快,如果您想跟进开发,请使用相同的版本。
Prefect有一些概念,我们尝试进行介绍。您可以查阅文档以获取更多详细信息。以下是来自Prefect文档的一些简要介绍:
流程(Flow):流程类似于函数。它们可以接受输入,执行工作并返回输出。实际上,您可以通过添加@flow装饰器将任何函数转换为Prefect流程。当函数成为流程时,其行为发生了变化,具有以下优势:
- 状态转换被报告给API,可以观察流程的执行过程。
- 输入参数类型可以进行验证。
- 发生故障时可以进行重试。
- 可以强制执行超时以防止无意间长时间运行的工作流。
任务(Task):任务本质上就是函数:它们可以接受输入,执行工作并返回输出。Prefect任务可以做几乎任何Python函数可以做的事情。使用@task装饰器将函数标记为任务。在流程函数内部调用任务会创建一个新的任务运行。
基础设施(Infrastructure):用户可以在创建部署时指定基础设施模块。该模块用于在运行时为部署创建的流程运行指定基础设施。基础设施只能与部署一起使用。当直接调用流程来运行时,您需要负责流程执行的环境。基础设施附属于部署,并传播到为该部署创建的流程运行中。基础设施由代理程序反序列化,并负责两个任务:
- 为流程运行创建执行环境的基础设施。
- 在基础设施中运行Python命令,启动Prefect引擎,从存储中检索流程并执行它。
- 基础设施针对流程运行的环境进行了特定配置。Prefect目前提供以下基础设施类型:
- Process:在本地子进程中运行流程。
- DockerContainer:在Docker容器中运行流程。
- KubernetesJob:在Kubernetes作业中运行流程。
任务运行器(Task runner):任务运行器允许您使用特定的执行器来执行Prefect任务,例如用于任务的并发、并行或分布式执行。任务运行器不是必需的,如果直接调用任务函数,任务将作为普通的Python函数执行,并返回函数返回的结果。
Prefect目前提供了以下内置的任务运行器:
- SequentialTaskRunner:可以按顺序运行任务。
- ConcurrentTaskRunner:可以并发运行任务,允许任务在阻塞IO时进行切换。任务将被提交到由anyio维护的线程池中。
此外,Prefect还提供了一些由Prefect开发的用于并行或分布式任务执行的任务运行器,可以安装为Prefect Collections。
- DaskTaskRunner:可以使用dask.distributed执行需要并行执行的任务。
- RayTaskRunner:可以使用Ray执行需要并行执行的任务。
在我们的情况下,我不想使用这些功能,而是只想按顺序运行任务,这是默认设置。
部署(Deployments):部署是一个服务器端的概念,它封装了一个流程(flow),使其可以通过API进行调度和触发。部署存储有关流程代码存储位置和运行方式的元数据。
所有Prefect流程运行都由API进行跟踪。API不需要提前注册流程。使用Prefect,您可以在本地或远程环境中调用流程,并进行跟踪。
创建Prefect工作流程的部署意味着打包工作流程代码、设置和基础设施配置,以便可以通过Prefect API进行管理,并由Prefect代理程序在远程环境中运行。
在创建部署时,用户必须回答两个基本问题:
- 代理程序需要什么指令来为我的工作流程设置执行环境?例如,工作流程可能具有Python依赖项、唯一的Kubernetes设置或Docker网络配置。
- 代理程序如何访问流程代码的位置和方式?
部署还使您能够:
- 计划流程运行
- 为工作队列和Prefect UI中的流程运行分配标签以进行过滤
- 根据部署为流程运行分配自定义参数值
- 通过API或Prefect UI创建临时流程运行
- 将流程文件上传到定义的存储位置,以便在运行时检索
部署可以打包您的流程代码,并将清单传递给API(可选择Prefect Cloud或使用prefect Orion start在本地运行的Prefect Orion服务器)。
在本文例子中,我只在本地运行Prefect,并不在Docker、Kubernetes或云端进行任何部署。稍后,我将讨论在云端运行Prefect的可能选项。
存储(Storage):存储功能让您可以配置部署的工作流程代码在Prefect代理程序中如何持久化和检索。每当构建一个部署时,存储块用于将包含工作流程代码(以及支持文件)的整个目录上传到配置的位置。这有助于确保相对导入、配置文件等的可移植性。
目前,部署存储块的选项包括:
- 本地文件系统:将数据存储在运行的本地文件系统中。
- 远程文件系统:将数据存储在支持fs规范的任何文件系统中。
- AWS S3存储:将数据存储在AWS S3存储桶中。
- Google Cloud存储:将数据存储在Google Cloud Platform(GCP)的Cloud Storage存储桶中。
这些存储选项可满足不同需求,您可以根据具体情况选择适合的存储方式来管理和检索工作流程代码。
工作队列和代理程序:工作队列和代理程序连接Prefect Orion编排环境与用户的执行环境。工作队列定义要执行的工作,代理程序轮询特定的工作队列以获取新的工作。
您在服务器上创建一个工作队列。工作队列收集与其过滤条件匹配的部署的调度运行。
您在执行环境中运行代理程序。代理程序会轮询特定的工作队列以获取新的流程运行,从服务器中获取调度的流程运行,并部署它们进行执行。
工作队列组织代理程序可以执行的工作。工作队列的配置决定了将要执行的工作。
工作队列中包含与队列标准匹配的任何部署的调度运行。标准基于部署标签,与队列上定义的标签相匹配的部署的所有运行将被选中。
这些标准可以随时修改,请求特定队列的代理程序进程只会查看匹配的流程运行。
代理程序进程是轻量级的轮询服务,从工作队列中获取调度的工作,并部署相应的流程运行进行执行。
调度(Schedules):调度告诉Prefect API如何自动按照指定的周期为您创建新的流程运行。
您可以为任何流程部署添加调度。Prefect调度器服务定期检查每个部署,并根据为部署配置的调度创建新的流程运行。
Prefect支持多种类型的调度,涵盖了广泛的用例,并提供了很大程度上的定制化:
- Cron调度最适合那些之前已经熟悉了cron的用户。
- Interval调度最适合需要按照一定的节奏运行,而与绝对时间无关的部署。
- Rule调度最适合依赖于日历逻辑的简单循环调度、不规则间隔、排除或者月份调整的部署。
我们将Prefect添加到包含我们代码的Python脚本中。我将继续使用上一篇博文中的Keras代码,尽管对于其他Scikit-Learn包,方法是相同的。基本上,我们获取之前的代码,包括所有与MLflow相关的信息,并将其转换为函数作为我们的流水线步骤。将python函数转换为Prefect步骤和流程非常简单,只需使用@task和@flow装饰器包装函数即可。在我们的情况下,训练模型的代码可能如下所示:
import numpy as np
import pandas as pd
import os
import nltk
import re
if os.path.exists('./corpora'):
os.environ["NLTK_DATA"] = "./corpora"
else:
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import mlflow
import pickle
from prefect import flow, task
from prefect.task_runners import SequentialTaskRunner
## data loading
@task(
name="read data",
tags=["data"],
retries=3,
retry_delay_seconds=60
)
def read_data(filename='Womens Clothing E-Commerce Reviews.csv'):
data = pd.read_csv(filename,index_col =[0])
print("Data loaded.\n\n")
return data
## preprocess text
@task(
name="preprocess data",
tags=["data"],
retries=3,
retry_delay_seconds=60
)
def preprocess_data(data):
#check if data/corpus is created before or not
if not os.path.exists('data/corpus_y.pickle'):
print("Preprocessed data not found. Creating new data. \n\n")
data = data[~data['Review Text'].isnull()] #Dropping columns which don't have any review
X = data[['Review Text']]
X.index = np.arange(len(X))
y = data['Recommended IND']
corpus =[]
for i in range(len(X)):
review = re.sub('[^a-zA-z]',' ',X['Review Text'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review =[ps.stem(i) for i in review if not i in set(stopwords.words('english'))]
review =' '.join(review)
corpus.append(review)
with open('data/corpus_y.pickle', 'wb') as handle:
pickle.dump((corpus, y), handle)
else:
print("Preprocessed data found. Loading data. \n\n")
with open('data/corpus_y.pickle', 'rb') as handle:
corpus, y = pickle.load(handle)
print("Data preprocessed.\n\n")
return corpus, y
## tokenization and dataset creation
@task(
name="create dataset",
tags=["data"],
retries=3,
retry_delay_seconds=60
)
def create_dataset(corpus, y, test_size=0.2, random_state=0):
tokenizer = Tokenizer(num_words = 3000)
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
padded = pad_sequences(sequences, padding='post')
X_train, X_test, y_train, y_test = train_test_split(padded, y, test_size = 0.20, random_state = 0)
print("Dataset created.\n\n")
return X_train, X_test, y_train, y_test, tokenizer
# mlflow.tensorflow.autolog()
@task(
name="tran model",
tags=["model"],
retries=3,
retry_delay_seconds=60
)
def train_model(X_train, y_train, X_test, y_test, tokenizer):
for embedding_dim, batch_size in zip([32, 64, 128], [32, 64, 128]):
with mlflow.start_run():
## model definition
model = tf.keras.Sequential([
tf.keras.layers.Embedding(3000, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
## training
num_epochs = 50
callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
min_delta=0,
patience=2,
verbose=0,
mode="auto",
baseline=None,
restore_best_weights=False,
)
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
mlflow.set_tag("developer", "Isaac")
mlflow.set_tag("algorithm", "Deep Learning")
mlflow.log_param("train-data", "Womens Clothing E-Commerce Reviews")
mlflow.log_param("embedding-dim", embedding_dim)
print("Fit model on training data")
model.fit(
X_train,
y_train,
batch_size=batch_size,
epochs=num_epochs,
callbacks=callback,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(X_test, y_test),
)
## save model and tokenizer
# model.save('models/model_dl.h5')
mlflow.keras.log_model(model, 'models/model_dl')
with open('models/tf_tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
mlflow.log_artifact(local_path="models/tf_tokenizer.pickle", artifact_path="tokenizer_pickle")
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(X_test, y_test, batch_size=128)
print("test loss, test acc:", results)
mlflow.log_metric("loss", results[0])
mlflow.log_metric("accuracy", results[1])
print("Model training completed.\n\n")
@flow(
name="Sentiment-Analysis-Flow",
description="A flow to run the pipeline for the customer sentiment analysis",
task_runner=SequentialTaskRunner()
)
def main():
tracking_uri = "sqlite:///mlflow.db"
model_name = "customer-sentiment-analysis"
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(model_name)
data = read_data()
corpus, y = preprocess_data(data)
X_train, X_test, y_train, y_test, tokenizer = create_dataset(corpus, y)
train_model(X_train, y_train, X_test, y_test, tokenizer)
if __name__ == '__main__':
main()
在训练模型后,您可以前往MLflow用户界面,决定是否想要在“生产”阶段更改模型。然后,您可以使用以下代码片段轻松加载“生产”阶段的模型,并按需进行评估(也许为此创建另一个流水线):
from mlflow.tracking import MlflowClient
def get_best_model(model_name, client):
model = mlflow.keras.load_model(f"models:/{model_name}/production", dst_path=None)
for mv in client.search_model_versions(f"name='{model_name}'"):
if dict(mv)['current_stage'] == 'Production':
run_id = dict(mv)['run_id']
artifact_folder = "models_pickle" #tokenizer_pickle
client.download_artifacts(run_id=run_id, path=artifact_folder, dst_path='.')
with open(f"{artifact_folder}/tf_tokenizer.pickle", 'rb') as handle:
tokenizer = pickle.load(handle)
print("Model and tokenizer loaded.\n\n")
return model, tokenizer
def test_model(model, X_test, tokenizer):
# Generate predictions (probabilities -- the output of the last layer)
# on new data using `predict`
print("Generate predictions for 3 samples")
predictions = model.predict(X_test[:3])
print("predictions shape:", predictions.shape)
sample_string = "I Will tell my friends for sure"
sample = tokenizer.texts_to_sequences(sample_string)
padded_sample = pad_sequences(sample, padding='post').T
sample_predict = model.predict(padded_sample)
print(f"model prediction for input: {sample_string} \n {sample_predict}")
if __name__ == '__main__':
tracking_uri = "sqlite:///mlflow.db"
model_name = "customer-sentiment-analysis"
client = MlflowClient(tracking_uri=tracking_uri)
model, tokenizer = get_best_model(model_name, client)
test_model(model, X_test, tokenizer)
通过将函数包装成Prefect任务,您将获得更多的日志信息,有助于观察和调试流水线。您可以运行以下命令来查看Prefect UI仪表板:
prefect orion start
对于我们的代码,这是截图:
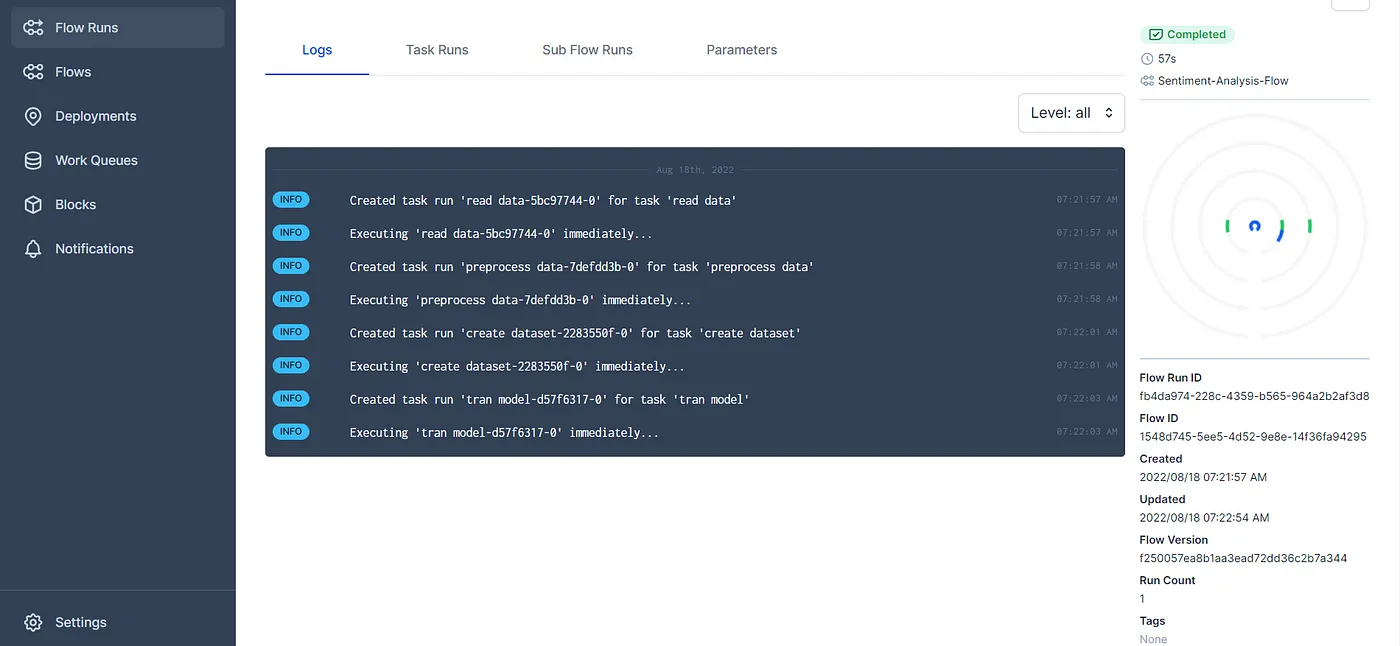
您可以查看不同任务的日志以及我们代码的流程。您还可以从仪表板获得更多信息。所以请随意尝试。 Prefect有许多有趣的功能。我非常喜欢它的并发、并行和异步支持。
您可以观看以下视频来了解更多关于Prefect的内容:
之前我曾写过关于另一个编排工具AirFlow的文章,您可以在这里找到。Prefect是一个非常好的替代方案。它更简单,没有AirFlow使用和调试时的复杂性。我非常推荐将其用于数据工作流和ETL任务。
正如我在文章开头提到的,实际上在这个项目中我们并不需要Prefect,我也不打算将其部署在云端。但是我会讨论如何在类似GCP的云服务上使用Prefect。
Prefect社区在他们的Slack中建议,如果您确实想在云端使用Prefect,可以使用Prefect Cloud。但是我对这个解决方案不感兴趣,因为我想在一个云平台(如GCP)上集成所有服务。
在云端使用Prefect的一种方式是创建一个虚拟机(VM)并在其中运行Prefect。根据任务和计算需求的不同,您可以选择使用更强大的虚拟机,例如搭载GPU的虚拟机。在这种情况下,如果您希望有一个调度计划,并使用Prefect来触发任务,那么您需要一直保持虚拟机和Prefect处于运行状态,如果使用搭载GPU的虚拟机,这可能会非常昂贵。但是,这对于数据流水线和ETL任务来说是可行的。
如果您想在GCP上使用Terraform来配置Prefect服务器,您可以查看这个代码段。它仅涉及将服务器部署到一个虚拟机上。
对于需要使用GPU的流程,一种解决方案可能是使用一个虚拟机来运行Prefect Orion,另外再使用一个搭载GPU的虚拟机来运行任务。您可以查看这个页面来了解如何使用API启动和停止虚拟机。另外,您还可以将任务容器化,并使用虚拟机来运行任务。您还可以使用Cloud Run和Cloud Function来运行流程,并由运行服务器的虚拟机触发。请注意,Cloud Run和Cloud Function在时间和资源上都有一些限制,虚拟机可能会给您更多的灵活性。
另一种解决方案是在一个具有所需规格的虚拟机上运行Prefect流程,并使用Google Workflows来触发它。在这种情况下,您将不使用Prefect的调度功能。您可以查看这里和这里以了解更多信息。
您还可以通过prefect-gcp库与BigQuery、Storage和Secret Manager进行交互。
对于大型公司的结构化数据团队,更具扩展性的解决方案是在Docker和Kubernetes上运行流程。
我还注意到在Prefect 1.0中,他们提供了在Vertex AI上运行流程的解决方案,Vertex AI是谷歌的无服务器和托管的机器学习服务。您可以在Vertex AI上运行流程并配置所使用的机器。流程完成后,机器将关闭。但这个功能在Prefect 2.0中尚未可用,将很快推出。
此外,您可以观看以下视频,了解如何在AWS的虚拟机上使用Prefect:
这就是本篇文章的全部内容。在接下来的博文中,我们将介绍ZenML。
请注意:当我学到更多关于在云端部署Prefect时,我将更新此篇文章。
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2023/09/10/mlops-project-part-2a-machine-learning-workflow-orchestration-using-prefect/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)