原文:Learn the Core of MLOps — Building Machine Learning (ML) Pipelines
实现MLOps以使AI工作的实用指南
MLOps 的必要性
众所周知,为了让AI发挥作用,真正的挑战不在于构建一个机器学习(ML)模型,而在于构建一个集成的ML系统,并持续地在生产环境中运行。这就是为什么提出了MLOps概念的原因,它正在迅速获得数据科学家、机器学习工程师和AI爱好者的关注。
近年来,机器学习算法在不断进步,AI和ML在组织中展示了巨大的潜力,这些潜力包括创造新的商业机会、提供更好的客户体验、提高运营效率等等。然而,在Jupyter Notebook中训练ML模型和将ML模型部署到生产系统之间存在巨大的技术鸿沟。因此,许多公司还没有找到实现其ML / AI目标的途径,他们求助于MLOps以获得帮助,希望通过MLOps,他们可以在真实世界的生产环境中实现AI工作,从而真正从AI和ML驱动的解决方案中获益。
因此,我认为编写一系列实用的指南来解释如何实施MLOps实践会非常有用。这些指南将包括对MLOps关键组件的解释、设计考虑因素以及实现示例代码。
如果我们从工程和实施的角度来看待MLOps,那么任何端到端的MLOps解决方案都有三个核心部分:
- 第一部分是——数据和特征工程管道
- 第二部分是——ML模型训练和再训练管道
- 第三部分是——ML模型推断和服务管道
MLOps以自动化方式将上述三个管道结合在一起,并确保ML解决方案是可靠、可测试和可重复的。在本博客的剩余部分中,我将逐个解释这三个管道。

Photo by Hitesh Choudhary on Unsplash
实施MLOps解决方案的关键构建模块
下图展示了MLOps上述三个管道的所有关键组件。可以看到,构建端到端的MLOps解决方案可能相当复杂,但请不要担心,我将在接下来的系列文章中逐一详细解释这些组件,并演示如何实现每个组件。
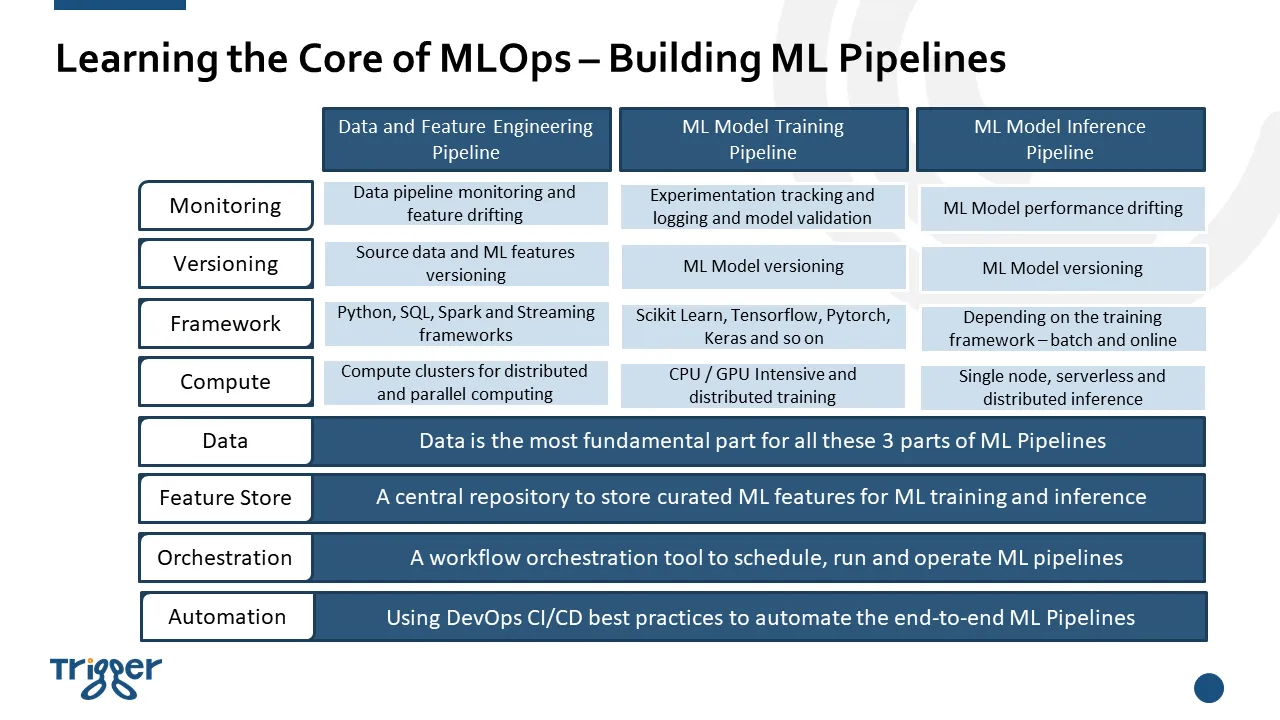
Learning the core of MLOps — Building ML Pipelines (Image by Author)
数据和特征工程管道
我们将从数据和特征工程管道开始,因为数据是任何机器学习系统的核心。一般来说,数据管道指的是提取、转换和加载(ETL)管道,通过这些管道,数据工程师从源系统中获取原始数据,然后清理并转换数据,将其转化为可靠且高质量的信息,供下游数据消费者使用。如果您有兴趣了解如何构建数据管道,我有一个单独的文章论述此事。请阅读《学习数据工程的核心——构建数据管道》。
机器学习的独特之处在于,原始数据需要被转换成特征,以便机器学习模型能够从数据中有效地学习有用的模式。将原始数据转换成特征的过程被称为特征工程。因此,本文的重点将围绕实现特征工程管道以及介绍特征存储的概念展开。
有各种特征工程技术,包括插补、处理异常值、分箱、对数转换、独热编码等等。如果你想了解更多,可以搜索一下,会有很多关于特征存储的博客文章。然而,我在这里要强调的是,一般情况下,对于一个机器学习(ML)项目,数据科学家会花费大量时间和精力进行特征工程,以获得机器学习模型的良好性能。因此,将这些特征存储起来以供发现和重用是有价值且必要的。因此,我们提出了“特征存储”这一概念,目前有一些开源和商业的特征存储解决方案。然而,特征存储不仅仅用于特征重用。特征存储是机器学习的数据管理层,允许您共享和发现特征,并创建更有效的机器学习流水线。 特征存储可以在任何MLOps解决方案的两个最重要的部分——模型训练和模型服务中发挥作用。总之,特征存储提供以下功能和好处:
- 特征的发现和重用
- 用于模型训练和服务的一致的特征工程
- 监测数据和特征漂移
- 训练数据集的可复现性
对于完整的MLOps解决方案,必须为模型训练和服务设置特征工程流程和特征存储。这只是一个非常高级的介绍。我将很快发布一篇专门介绍特征存储的博客文章。如果您想在新博客发布时收到通知,请随时关注我的动态。
ML模型推理/服务流程
一旦模型经过训练和评估,下一步就是将模型放入真实的生产环境中供使用。通常有两种方法来提供经过训练的ML模型:
离线批量推理:按照一定的频率调用ML模型进行预测。频率可以是每日、每周,甚至更长时间,也可以是每分钟甚至更低。当频率非常低(非常频繁)时,您可以将流数据流水线与ML模型推理集成。当批量推理的数据量非常大时,需要使用分布式计算框架。例如,您可以将模型作为Spark用户定义函数(UDF)加载,并使用分布式计算进行并行推理。
在线实时推理:ML模型打包为REST API端点。对于在线实时推理,打包的ML模型通常嵌入到应用程序中,在收到请求时生成模型预测。当请求量较大时,可以将模型打包为容器镜像,并部署在Kubernetes环境中进行自动扩展,以响应大量预测请求。
正如前面稍微解释的那样,数据决定了模型的性能。在现实世界中,数据总是在变化的,模型的性能也很可能会随之变化,通常是恶化。因此,具备一个监控解决方案来跟踪生产模型以及用于训练模型的数据/特征的变化非常必要。一旦发现显著的变化,监控解决方案需要能够触发模型重新训练,或者向相关团队发送通知,以便立即进行修复。对于关键业务的ML驱动应用程序而言,这尤为重要。通常,ML模型监控包括以下四个类别:
- 预测漂移
- 数据/特征漂移
- 目标漂移
- 数据质量
在ML监控方案中,既有开源解决方案,也有商业解决方案。例如,Evidently AI是一个开源的Python库,用于从验证到生产环境评估、测试和监控ML模型的性能。
到目前为止,我们已经涵盖了完整MLOps解决方案的三个关键流程-数据和特征工程流程、ML模型训练和重新训练流程、以及ML模型推理流程,以及ML模型监控。ML模型训练和重新训练流程
完成特征工程后,下一步将是ML模型训练。ML模型训练是一个高度迭代的过程,因此也被称为ML模型实验。数据科学家需要运行许多实验,尝试不同的参数和超参数,以找到性能最佳的模型。因此,数据科学家需要一种系统化的方法来记录和跟踪每个实验运行的超参数和指标,以便比较每个运行并找到最佳的模型。有一些开源库可以帮助数据科学家记录和跟踪模型实验,例如mlflow。mlflow是一个开源平台,用于管理机器学习的生命周期,包括实验、可复现性、部署和中央模型注册。
除了模型训练,数据科学家还需要在将模型放入实际生产环境之前对其进行评估和测试。他们需要确保模型在真实世界的实时数据上表现良好,就像在训练数据上一样。因此,选择正确的测试数据集和选择最相关的性能指标非常重要。通过MLOps,模型训练和模型评估都需要自动化。
ML驱动系统的关键挑战在于模型性能取决于用于训练的数据。然而,数据总是在变化的。因此,对于大多数ML驱动场景来说,重新训练模型变得非常必要。通常有几种触发模型重新训练的方式:
基于时间表的触发:模型以预定义的间隔进行重新训练,例如每周一次。根据数据的变化速度和其他业务需求,时间表的频率可能会有很大的差异。 基于触发器的触发:当发现漂移时,如数据漂移、特征漂移或模型性能下降,将触发模型重新训练。为了实现完全自动化的模型重新训练,需要一个强大的监控解决方案来监控数据变化和模型变化。
MLOps解决方案的理想结果不仅是自动重新训练模型,而且还能评估新训练的模型并根据预定义的模型指标选择最佳运行结果。
MLOps解决方案的规模范围
MLOps是一个相当新的概念,你可能从上面的介绍中可以看出,MLOps涉及将许多不同的组件组合在一起,以使人工智能在现实世界中发挥作用。因此,许多人认为MLOps很困难和复杂。然而,当我们谈论实施端到端的MLOps解决方案时,需要绘制一个规模范围。
例如,如果您的ML解决方案是小规模的批处理方式-批处理数据流水线,批处理训练和推理,并且数据量不需要分布式计算-那么实施MLOps并不困难,甚至一个数据科学家也可以成为“全栈”,拥有整个解决方案。然而,如果您谈论的是大规模、持续训练和实时推理,那可能会相当复杂,需要多个团队和不同的基础设施进行协同工作。
因此,在接下来的文章中,我将解释一些ML参考架构以及在不同规模下实施MLOps的最佳实践,因为不同的规模可能涉及非常不同的技能集和不同的基础设施设置。敬请关注。
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2023/09/13/learn-the-core-of-mlops-building-machine-learning-ml-pipelines/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
