原文:Cracking Open the OpenAI (Python) API
一个完整的面向初学者友好的介绍,附带示例代码。
 Photo by Martin Sanchez on Unsplash
Photo by Martin Sanchez on Unsplash
这是关于实际应用大型语言模型(LLM)系列的第二篇文章。在这里,我将为初学者提供一个友好的OpenAI API入门介绍。这使您能够超越像ChatGPT这样的受限聊天界面,更好地利用LLM来满足您独特的用例。以下是提供的Python示例代码,并可在GitHub存储库中找到。
目录:
- 什么是 API?
- OpenAI 的(Python)API
- 入门指南(4个步骤)
- 示例代码
在这个系列的第一篇文章中,我将提示工程描述为在实践中使用 LLM 最容易掌握的方法。而最简单(也是最受欢迎)的方式是通过像ChatGPT这样的工具,它提供了一种直观、无需费用和无需编码的方式与LLM进行交互。
A Practical Introduction to LLMs
然而,这种易用性是以牺牲一些方面为代价的。具体而言,聊天界面的限制性使其无法很好地适用于许多实际应用场景,例如构建自己的客服机器人,实时分析客户评价的情感等等。
针对这些情况,我们可以进一步发展提供给LLM的指令,并通过API以编程方式与其进行交互。
1) What’s an API?
一个应用程序编程接口(API)允许你以编程方式与远程应用程序进行交互。尽管这听起来可能有些技术性和复杂,但实际上,其概念非常简单。我们可以通过以下类比来理解。
想象一下,你突然对那次在萨尔瓦多度过的夏天里吃的普普萨产生了强烈的渴望。不幸的是,你已经回到家了,不知道在哪里能找到好吃的萨尔瓦多美食。幸运的是,你有一个非常热衷于美食的朋友,他知道城里的每家餐厅。
于是,你给朋友发了一条短信:
“城里有没有好吃的普普萨店?”
然后,几分钟后,你收到了回复:
“有!萨尔瓦多的风味(Flavors of El Salvador)有最好吃的普普萨!”
虽然这个例子似乎与API无关,但实际上这就是API的工作原理。你发送一个请求给远程应用程序,就像你给你的美食朋友发短信一样。然后,远程应用程序发送回一个响应,就像你朋友回你短信一样。
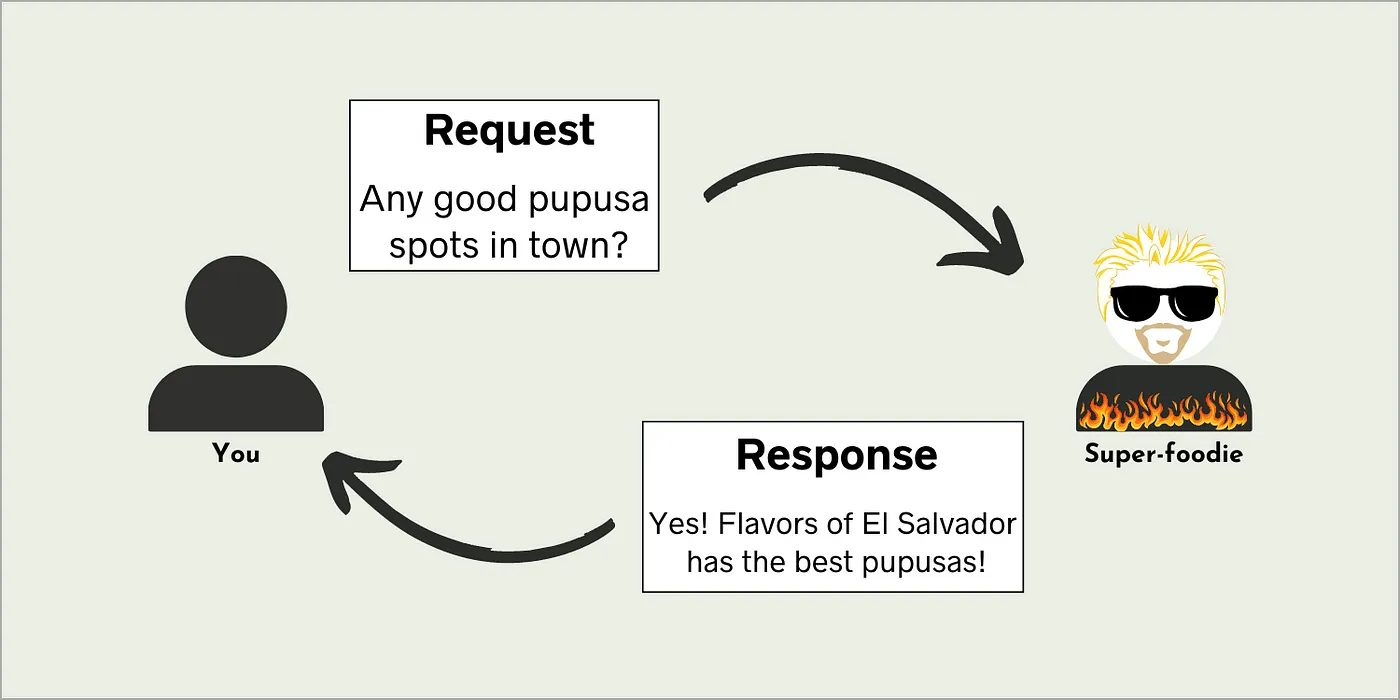 A visual analogy of how APIs work. Image by author.
A visual analogy of how APIs work. Image by author.
API与上面的类比的区别在于,你不是通过手机的短信应用发送请求,而是使用你喜欢的编程语言,如Python、JavaScript、Ruby、Java等。这对于开发需要使用外部信息的软件非常有用,因为信息的获取可以自动化处理。
2) OpenAI’s (Python) API
我们可以使用API与大型语言模型进行交互。其中一个流行的API是OpenAI的API,通过它,你可以使用Python将提示发送到OpenAI,并获取相应的回复,而不是在ChatGPT的网页界面中键入提示信息。
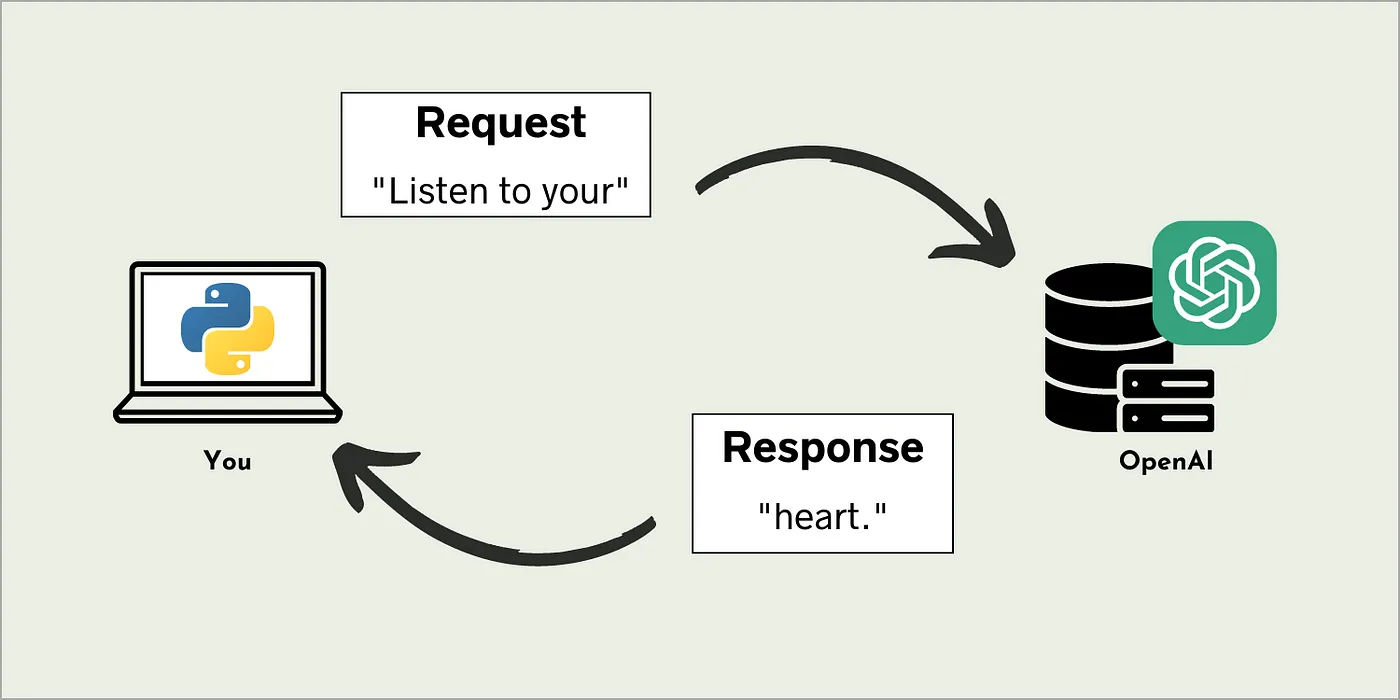 Visualization of how API calls to OpenAI works. Image by author.
Visualization of how API calls to OpenAI works. Image by author.
这样做使几乎任何人都能够访问最先进的LLM(以及其他ML模型),而无需为运行它们而提供计算资源。当然,缺点是OpenAI并非出于慈善目的提供这项服务。每个API调用都是需要付费的,稍后我们会详细讨论这个话题。
API的一些显著特点(ChatGPT中不可用)如下所列:
- 可自定义系统消息(ChatGPT默认显示为“我是ChatGPT,一款由OpenAI开发的基于GPT-3.5架构的大型语言模型,我的知识基于2021年9月以前的信息。今天是2023年7月13日。”)
- 可调整输入参数,例如最大回复长度、回复数量和温度(即回复的“随机性”)。
- 可以在提示中包含图片和其他文件类型。
- 可提取有益的词嵌入用于下游任务。
- 可输入音频进行转录或翻译。
- 模型微调功能。
OpenAI API提供了多个可供选择的模型。选择最适合的模型取决于你的具体用例。下面是当前可用的模型列表[1]。
 List of available models via the OpenAI API as of Jul 2023. Image by author. [1]
List of available models via the OpenAI API as of Jul 2023. Image by author. [1]
注意: 上述列出的每个项目都有一组不同大小和价格的模型可供选择。请查阅文档以获取最新信息。
Pricing & Tokens
尽管OpenAI API为开发人员提供了轻松访问最先进的ML模型,但显而易见的缺点是需要付费。定价是基于每个令牌(Token)计算的(不,我指的不是NFT或者你在游戏厅使用的东西)。
在LLM的上下文中,令牌(Token)实际上是表示一组单词和字符的一组数字。例如,”The” 可以是一个令牌,” end”(带有空格)是另一个令牌,”.” 是另一个令牌。 因此,文本 “The End.” 将由3个令牌组成,比如(73,102,6)。
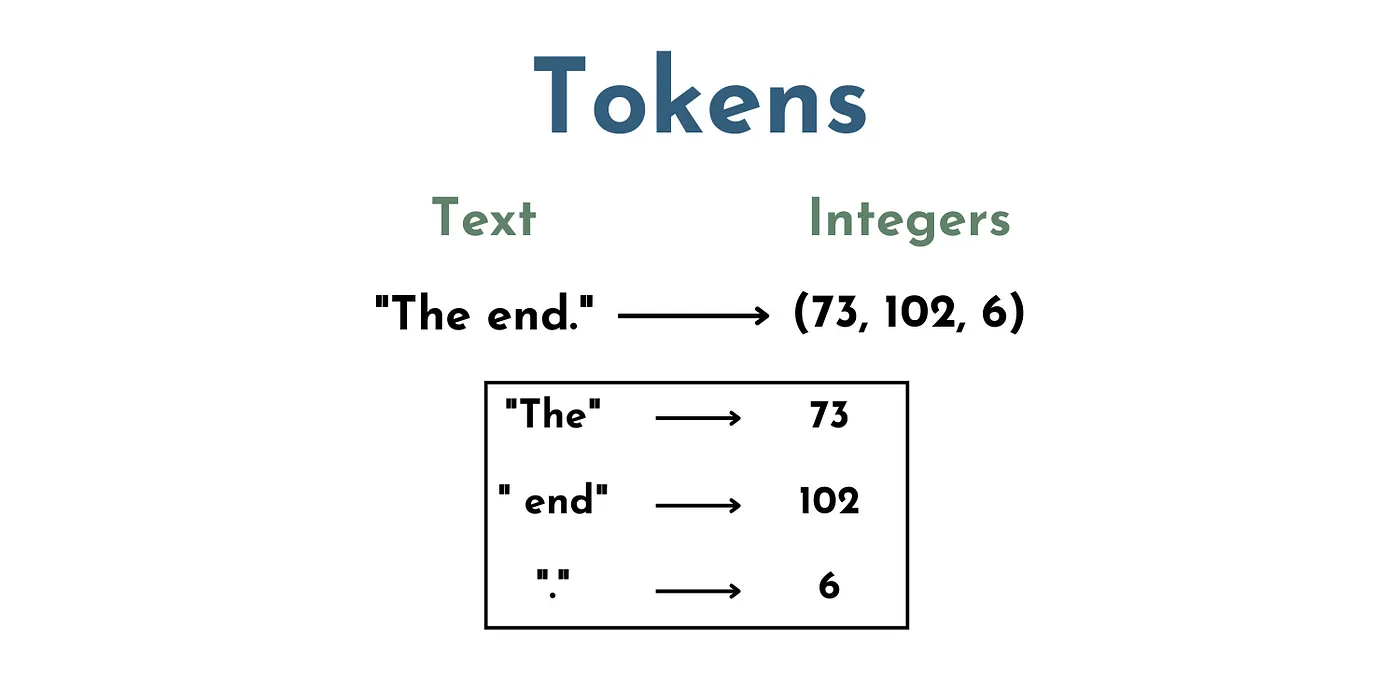 Toy example showing one possible token mapping between text and integers. Image by author.
Toy example showing one possible token mapping between text and integers. Image by author.
这是一个关键的步骤,因为LLM(即神经网络)不能直接“理解”文本。文本必须转换为数值表示,以便模型可以对输入进行数学运算。因此,需要进行令牌化处理。
API调用的价格取决于提示中使用的令牌数量和所选择的模型。每个模型的价格可以在OpenAI的网站上获得。
3) 入门指南(4个步骤)
现在,我们对OpenAI API有了基本的理解,让我们看看如何使用它。在开始编码之前,我们需要完成以下四个设置。
3.1) 创建账户(前三个月获得5美元的API额度)
- 要创建账户,请访问OpenAI API概述页面,在右上角点击“注册”。
- 注意:如果你之前使用过ChatGPT,那么你可能已经有一个OpenAI账户。如果是这样,请点击“登录”。
3.2) 添加支付方式
- 如果你的账户已经超过3个月,或者免费的5美元API额度对你来说不够,你需要在进行API调用之前添加一种支付方式。
- 点击你的个人图片,选择“管理账户”选项。
- 然后,通过点击“结算”选项卡,再点击“支付方式”,来添加一种支付方式。
3.3) 设置使用限制
- 接下来,我建议你设置使用限制,以避免超出预算的费用。
- 你可以在“结算”选项卡下找到“使用限制”。在这里,你可以设置“软限制”和“硬限制”。
- 如果你达到每月的软限制,OpenAI会发送电子邮件通知给你。
- 如果你达到硬限制,任何额外的API请求将被拒绝(因此,你不会被收取超出此限制的费用)。
3.4) 获取API秘钥
- 点击“查看API秘钥”。
- 如果是你第一次,你需要创建一个新的秘钥。要做到这一点,点击“创建新的秘钥”。
- 接下来,你可以为你的秘钥命名。这里我使用了“my-first-key”。
- 然后,点击“创建秘钥”。
4) Example Code: Chat Completion API
完成了所有的设置之后,我们(终于)准备好进行第一次API调用了。在这里,我们将使用OpenAI的Python库,它可以让你轻松地将OpenAI的模型集成到你的Python代码中。你可以通过pip来下载这个包。下面的示例代码(以及额外的代码)可以在本文的GitHub存储库中找到。
关于Completions API被弃用的一点说明:OpenAI正在让我们从一个非常简单的API调用开始。在这里,我们将使用openai.ChatCompletions.create()方法传递两个输入参数,即model和messages。
- model:定义要使用的语言模型的名称(我们可以从前面文章中列出的模型中进行选择)。
- messages:将“先前”的对话设置为字典列表。每个字典有两个键值对(例如
{ "role": "user", "content": "Listen to your" })。首先,“role”定义了谁在说话(例如"role":"user"),这可以是"user"、"assistant"或"system"。其次,“content”定义了角色说的内容(例如"content":"Listen to your")。虽然这可能比自由形式的提示界面更加限制,但我们可以在输入的对话中进行创意,以优化特定用例的响应(稍后我们会详细介绍)。
以下是我们在Python中进行的第一个API调用的示例代码。摒弃自由形式的提示范例,转向基于对话的API调用。根据OpenAI的博客文章,基于对话的范例利用了结构化的提示界面,提供了更好的响应,与之前的范例相比[2]。
尽管旧版的OpenAI模型(GPT-3)仍然通过“自由形式”范例提供,但更新和更强大的模型(如GPT-3.5-turbo和GPT-4)只能通过基于对话的方式调用。
import openai
from sk import my_sk # importing secret key from external file
import time
# imported secret key (or just copy-paste it here)
openai.api_key = my_sk
# create a chat completion
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Listen to your"}])
API的响应结果存储在chat_completion变量中。打印chat_completion,我们可以看到它类似于一个包含6个键值对的字典。
{'id': 'chatcmpl-7dk1Jkf5SDm2422nYRPL9x0QrlhI4',
'object': 'chat.completion',
'created': 1689706049,
'model': 'gpt-3.5-turbo-0613',
'choices': [<OpenAIObject at 0x7f9d1a862b80> JSON: {
"index": 0,
"message": {
"role": "assistant",
"content": "heart."
},
"finish_reason": "stop"
}],
'usage': <OpenAIObject at 0x7f9d1a862c70> JSON: {
"prompt_tokens": 10,
"completion_tokens": 2,
"total_tokens": 12
}}
每个字段的含义如下所示:
- ‘id’:API响应的唯一ID。
- ‘object’:发送响应的API对象的名称。
- ‘created’:API请求被处理的Unix时间戳。
- ‘model’:所使用的模型的名称。
- ‘choices’:以JSON格式(类似于字典)呈现的模型响应。
- ‘usage’:以JSON格式(类似于字典)呈现的令牌计数元数据。
然而,在这里我们主要关心的是”Choices”字段,因为模型的响应结果存储在这里。在这个例子中,我们可以看到”assistant”角色回复了消息”heart”。
太棒了!我们完成了第一次API调用。现在让我们开始尝试调整模型的输入参数。
max_tokens
首先,我们可以使用max_tokens输入参数来设置模型响应中允许的最大令牌数。根据使用情况,这可以有很多用途。在这种情况下,我只想要一个单词的回复,所以我将它设置为1个令牌。
# setting max number of tokens
# create a chat completion
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Listen to your"}],
max_tokens = 1)
# print the chat completion
print(chat_completion.choices[0].message.content)
"""
Output:
>>> heart
"""
n
接下来,我们可以设置我们希望从模型中接收的响应数量。同样,这根据使用情况可以有很多用途。例如,如果我们希望生成一组响应,然后从中选择我们最喜欢的一个。
# setting number of completions
# create a chat completion
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Listen to your"}],
max_tokens = 2,
n=5)
# print the chat completion
for i in range(len(chat_completion.choices)):
print(chat_completion.choices[i].message.content)
"""
Ouput:
>>> heart.
>>> heart and
>>> heart.
>>>
>>> heart,
>>>
>>> heart,
"""
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2023/10/09/cracking-open-the-openai-python-api/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
