原文:A Practical Introduction to LLMs
在实践中使用LLM的3个级别
这是一系列关于实际应用大型语言模型(LLMs)的文章中的第一篇。在这篇文章中,我将介绍LLMs并介绍与其相关的三个工作层次。未来的文章将探讨LLMs的实际应用方面,例如如何使用OpenAI公开的API,Hugging Face Transformers Python库,如何微调LLMs,以及如何从头开始构建LLM。
 Photo by Patrick Tomasso on Unsplash
Photo by Patrick Tomasso on Unsplash
什么是LLM?
LLM是Large Language Model的缩写,是人工智能和机器学习领域的一项最新创新。这种强大的新型人工智能于2022年12月随着ChatGPT的发布而病毒式传播。
对于那些并不深入涉足人工智能炒作和科技新闻的领域的人来说,ChatGPT是一个聊天界面,它运行在一个名为GPT-3的大型语言模型(LLM)之上。在撰写本文时,该模型已经升级到GPT-3.5或GPT-4版本。
如果您使用过ChatGPT,您就会明显感觉到它与传统的AOL即时通讯或信用卡客户服务的聊天机器人有所不同。
这个感觉不一样
什么使LLM“大”?
当我听到“大型语言模型”这个术语时,我的第一个问题是,这与“常规”语言模型有什么不同?
语言模型比大型语言模型更通用。就像所有的正方形都是矩形,但不是所有的矩形都是正方形。所有LLM都是语言模型,但并非所有语言模型都是LLM。
 大型语言模型是一种特殊的语言模型。作者图片
大型语言模型是一种特殊的语言模型。作者图片
好吧,LLM是一种特殊类型的语言模型,但是是什么让它们特别呢?
有两个关键属性可以区分大型语言模型(LLM)与其他语言模型。一个是定量的属性,另一个是定性的属性。
- 从数量上来说,区分一个大型语言模型(LLM)的特点是其使用的参数数量。目前的大型语言模型通常拥有大约1000亿到1000亿个参数[1]。
- 定性地说,当语言模型变得“大”时,会发生一些值得注意的事情。它表现出所谓的涌现特性。zero-shot learning [1].当语言模型达到足够大的规模时,这些属性似乎突然出现。
Zero-shot Learning Zero-shot学习
GPT-3(以及其他大型语言模型)的主要创新在于它可以在各种情境下进行零样本学习[2]。这意味着即使没有明确进行该任务的训练,ChatGPT也能执行该任务。
虽然这对我们高度进化的人类来说可能没什么大不了的,但这种零机会学习能力与之前的机器学习范式形成了鲜明的对比。
以前,模型需要明确地训练它要做的任务,以获得良好的性能。这可能需要1 k-1 M个预先标记的训练样本。
例如,如果你想让计算机进行语言翻译、情感分析和识别语法错误。这些任务中的每一个都需要一个专门的模型,该模型是在大量标记的示例集上训练的。然而,现在,LLM可以在没有明确培训的情况下完成所有这些事情。
LLM如何工作?
用于训练大多数最先进的LLM的核心任务是单词预测。换句话说,给定一个单词序列,下一个单词的概率分布是什么?
例如,给定序列“听你的_”,最有可能的下一个单词可能是:心脏、内脏、身体、父母、祖母等。这可能看起来像下面所示的概率分布。
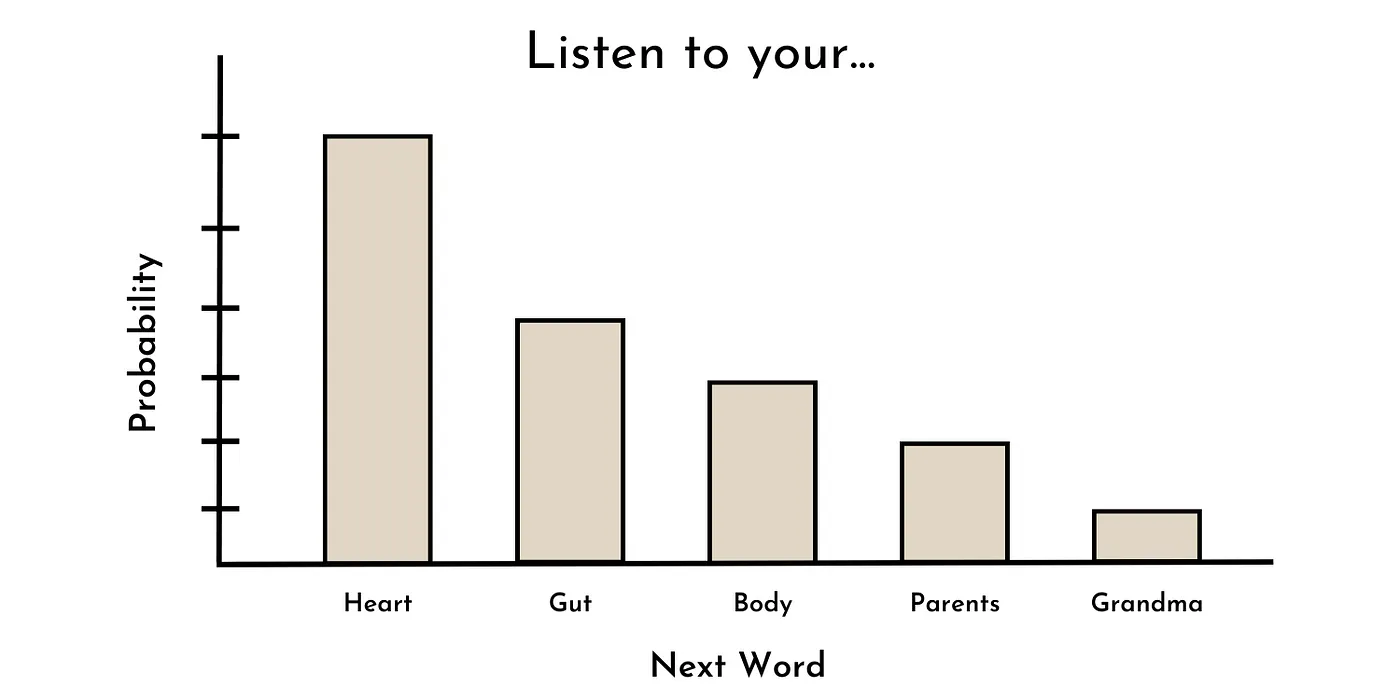
Toy probability distribution of next work in sequence “Listen to your ___.” Image by author.
有趣的是,过去许多(非大型)语言模型的训练方式与此类似(例如GPT-1)[3]。然而,由于某种原因,当语言模型的规模超过一定程度(约10亿个参数),这些(新兴的)能力,如零样本学习,可能会开始出现[1]。
虽然没有明确的答案来解释为什么会发生这种情况(目前只有猜测),但很明显,LLM是一种强大的技术,具有无数潜在的用例。
使用LLM的3个级别
现在,我们转向如何在实践中使用这种强大的技术。虽然有无数潜在的LLM用例,但在这里我将它们分为3个级别,按所需的技术知识和计算资源排序。我们从最容易接近的开始。
第1级:提示工程
在实践中,使用大型语言模型的第一层次是提示工程,我定义为不改变任何模型参数的情况下使用大型语言模型。虽然许多技术倾向的个体似乎对提示工程的概念不屑一顾,但这是实际应用中使用大型语言模型最易于掌握(无论从技术上还是经济上)的方式。
Prompt Engineering: How to Trick AI into Solving Your Problems
有两种主要的方式进行提示工程:简单方式和稍微困难的方式。
简单方式:ChatGPT(或其他便捷的大型语言模型用户界面)——这种方法的主要优点是便利性。像ChatGPT这样的工具提供了一种直观、免费且无需编程的方式来使用大型语言模型(没有比这更简单的了)。
然而,便利通常是以某种代价为代价的。在这种情况下,这种方法存在两个关键的缺点。首先,缺乏功能性。例如,ChatGPT不能轻松让用户自定义模型输入参数(如temperature或最大响应长度),这些参数可以调节大型语言模型的输出结果。其次,与ChatGPT用户界面的交互不能轻易地进行自动化处理,因此无法应用于大规模的使用情景中。
虽然这些缺点可能对某些使用情况造成影响,但如果我们进一步提升提示工程,这两个缺点都是可以得到改善的。
较困难的方式:直接与大型语言模型交互——我们可以通过通过编程接口直接与大型语言模型进行交互来克服ChatGPT的一些缺点。这可以通过公共API(如OpenAI的API)或在本地运行大型语言模型(使用类似Transformers的库)来实现。
虽然这种方式进行提示工程相对不太便利(因为需要编程知识和可能的API费用),但它提供了一种可定制、灵活且可扩展的实际使用大型语言模型的方式。本系列的未来文章将讨论付费和免费的方式来进行这种类型的提示工程。
虽然提示工程(根据此定义)可以处理大多数潜在的大型语言模型应用,但依赖通用模型可能会导致特定用例的性能不佳。对于这些情况,我们可以进一步提升使用大型语言模型的水平。
级别2:模型微调
使用大型语言模型的第二个层次是模型微调,我将其定义为利用至少一个(内部)模型参数(即权重和偏差)来调整现有的大型语言模型,以适应特定的用例。对于熟悉该领域的人来说,这是迁移学习的一个例子,即利用现有模型的某部分来开发另一个模型。
通常,模型微调包括两个步骤。第一步:获取一个预训练的大型语言模型。第二步:根据(通常是成千上万个)高质量标记的示例,更新模型参数以适应特定任务。
这种方法对于模型开发非常强大,因为相对较少的样本和计算资源就可以产生出色的模型性能。
然而,这种方法需要更多的技术专业知识和计算资源,相比于即时工程而言。在未来的文章中,我将尝试通过回顾微调技术并分享示例Python代码,以克服这些缺点。
Fine-Tuning Large Language Models (LLMs)
虽然提示工程和模型微调可以应对大多数大型语言模型应用的情况,但仍有一些情况需要进一步深入研究。
第3级:建立自己的LLM
在实践中使用大型语言模型的第三种也是最后一种方式是自己构建。在模型参数方面,这意味着您需要从零开始设计所有的模型参数。
大型语言模型的主要成果来自其训练数据。因此,在某些应用中,可能需要收集定制的、高质量的文本语料库用于模型训练,例如针对临床应用开发的医学研究语料库。
这种方法的最大优势是您可以完全根据特定的用例定制大型语言模型,具有最大的灵活性。然而,常常情况下,灵活性与便利性是相互牵制的。
由于大型语言模型性能的关键在于规模,从零开始构建大型语言模型需要巨大的计算资源和技术专长。换句话说,这不可能是一个独立的周末项目,而是一个需要团队全力工作数月甚至数年,配备7-8F的预算才能实现。
然而,在本系列的未来文章中,我们将探讨从零开始开发大型语言模型的流行技术。
结论
尽管大型语言模型(LLMs)引起了足够的炒作,但它们是人工智能领域的一项强大创新。在这里,我介绍了LLMs的基本知识,并说明了它们在实际应用中的用途。本系列的下一篇文章将为您提供OpenAI Python API的入门指南,以帮助您快速启动下一个LLMs用例。
| 👉 More on LLMs: OpenAI API | Hugging Face Transformers | Prompt Engineering | Fine-tuning | Build an LLM |
Cracking Open the OpenAI (Python) API
[1] Survey of Large Language Models. arXiv:2303.18223 [cs.CL]
[2] GPT-3 Paper. arXiv:2005.14165 [cs.CL]
[3] Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training. (GPT-1 Paper)
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2023/10/10/a-practical-introduction-to-llms/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)