原文: Cracking Open the Hugging Face Transformers Library
使用开源 LLM 的快速入门指南
这是一系列关于如何在实践中使用大型语言模型(LLMs)的第三篇文章。在这篇文章中,我将为初学者提供一个简明易懂的指南,介绍Hugging Face Transformers库。该库提供了一种简单且免费的方式来使用各种开源语言模型。我将从概念回顾开始,然后深入介绍示例Python代码。

Photo by Jéan Béller on Unsplash
在本系列前一篇文章中,我们探讨了OpenAI Python API并使用它制作了自定义聊天机器人。不过,该API的一个缺点是API调用需要花费资金,对于某些用例可能无法很好地扩展。
在这些情况下,使用开源解决方案可能更为有利。一种流行的做法是使用 Hugging Face 的 Transformers 库。
What is Hugging Face?
Hugging Face 是一家人工智能公司,已成为开源机器学习(ML)的主要中心。他们的平台有3个主要元素,允许用户访问和共享机器学习资源。
首先是他们快速增长的预训练开源机器学习模型库,用于自然语言处理(NLP)、计算机视觉等。其次,他们有用于训练机器学习模型的数据集库,几乎可以用于任何任务。最后,还有Spaces,这是Hugging Face托管的开源ML应用集合。
这些资源的优势在于它们是由社区生成的,利用了开源的所有优势(即免费、工具种类繁多、资源质量高、创新速度快)。虽然这些资源使得构建强大的机器学习项目比以前更容易,但Hugging Face生态系统还有另一个关键元素——Transformers库。
🤗Transformers
Transformers是一个Python库,使得下载和训练最先进的机器学习模型变得容易。虽然它最初是为了开发语言模型而开发的,但其功能已经扩展到包括计算机视觉、音频处理和其他模型的模型。
这个库的两个主要优点是,一,它可以很容易地与Hugging Face(前面提到的)模型、数据集和Spaces存储库集成,二,该库支持其他流行的机器学习框架,如PyTorch和TensorFlow。
这为下载、训练和部署机器学习模型和应用程序提供了一个简单而灵活的一站式平台。
Pipeline()
开始使用该库的最简单方法是使用pipeline()函数,它将自然语言处理(和其他)任务抽象成一行代码。例如,如果我们想进行情感分析,我们需要选择一个模型,对输入文本进行标记化,将其传递给模型,并解码数字输出以确定情感标签(正面或负面)。
虽然这看起来可能有很多步骤,但我们可以使用pipeline()函数在1行中完成所有这些步骤,如下面的代码片段所示。
pipeline(task="sentiment-analysis")("Love this!")
# output -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]
当然,情感分析不是我们在这里唯一可以做的事情。几乎任何NLP任务都可以通过这种方式完成,例如摘要、翻译、问答、特征提取(即文本嵌入)、文本生成、零分类等等——完整的内置任务列表可以在pipeline()文档中找到。
在上面的示例代码中,因为我们没有指定模型,所以使用了情感分析的默认模型(即distilbert-base-uncased-finetuned-sst-2-english)。但是,如果我们想更明确一些,我们可以使用以下代码行。
pipeline(task="sentiment-analysis",
model='distilbert-base-uncased-finetuned-sst-2-english')("Love this!")
# ouput -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]
Transformers库的最大好处之一是,我们只需简单地更改传递给pipeline()函数的模型名称,就可以轻松地使用Hugging Face的模型存储库中28,000多个文本分类模型中的任何一个。
Models
在Hugging Face上有一大批预训练模型(截至撰写本文时为277,528个)。几乎所有这些模型都可以通过Transformers轻松使用,使用我们在上面的代码块中看到的相同语法。
然而,Hugging Face上的模型不仅适用于Transformers库。还有其他流行机器学习框架的模型,例如PyTorch,Tensorflow,Jax。这使得Hugging Face的模型存储库对Transformers库之外的机器学习从业者非常有用。
要了解浏览存储库的样子,让我们考虑一个例子。假设我们想要一个可以进行文本生成的模型,但我们希望它可以通过Transformers库获得,这样我们就可以在一行代码中使用它(就像我们在上面做的那样)。我们可以轻松地使用“任务”和“库”过滤器查看符合这些标准模型。
符合这些标准的模型是新发布的Llama 2。更具体地说,Llama-2–7b-chat-hf是Llama 2系列模型之一,拥有约70亿个参数,针对聊天进行了优化,并且采用Hugging Face Transformers格式。我们可以通过模型卡片了解更多有关此模型的信息,如图所示。
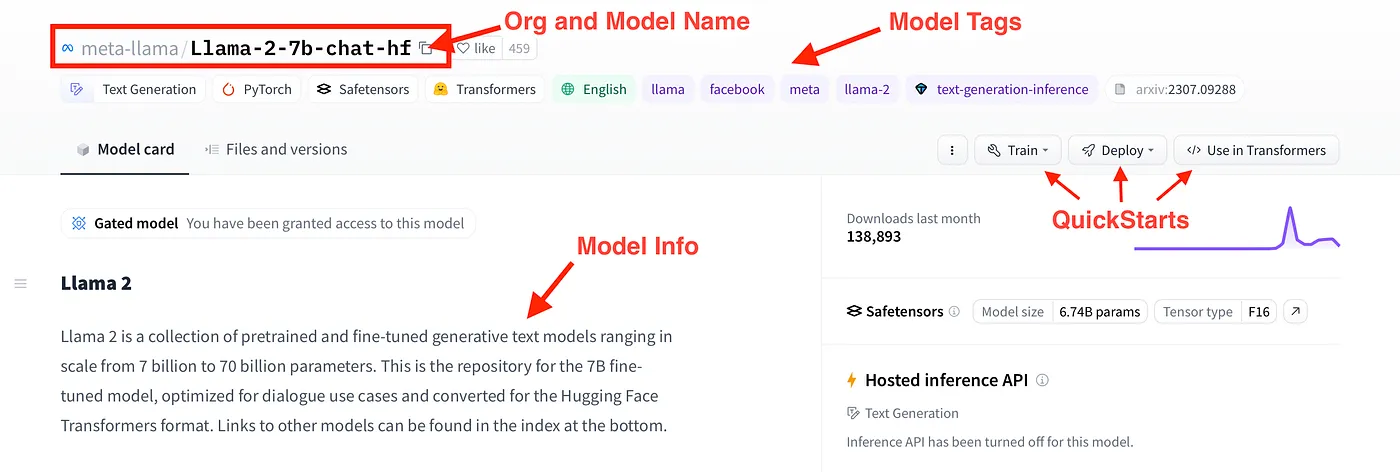
Touring the Llama-2–7b-chat-hf model card. Image by author.
Installing 🤗Transformers (with Conda)
现在我们对Hugging Face和Transformers库提供的资源有了基本了解,让我们看看如何使用它们。我们从安装库和其他依赖项开始。
Hugging Face在其网站上提供了一个安装指南。因此,我不会尝试在此处重复该指南。但是,我将为下面的示例代码提供一个快速的2步指南,说明如何设置conda环境。
步骤1)第一步是下载可在GitHub存储库中找到的hf-env.yml文件。您可以直接下载该文件或克隆整个存储库。
步骤2)接下来,在您的终端(或Anaconda命令提示符)中,您可以使用以下命令基于hf-env.yml创建一个新的conda环境:
>>> cd <directory with hf-env.yml>
>>> conda env create --file hf-env.yml
安装可能需要几分钟的时间,但一旦完成,您应该就可以准备出发了!
Example Code: NLP with 🤗Transformers
安装了必要的库后,让我们来看一些示例代码。在这里,我们将使用pipeline()函数来调查3个NLP用例,即情感分析、总结和对话文本生成。
最后,我们将使用Gradio为这些用例中的任何一个快速生成用户界面(UI),并将其部署到Hugging Face Spaces上作为应用程序。所有示例代码都可以在GitHub存储库中找到。
情感分析(Sentiment Analysis)
我们开始进行情感分析。回想一下,之前我们使用管道函数执行类似于下面的代码块的操作,其中我们创建了一个分类器,可以将输入文本标记为正面或负面。
from transformers import pipeline
classifier = pipeline(task="sentiment-analysis", \
model="distilbert-base-uncased-finetuned-sst-2-english")
classifier("Hate this.")
# output -> [{'label': 'NEGATIVE', 'score': 0.9997110962867737}]
更进一步,我们可以将列表传递给分类器,而不是一个接一个地处理文本,以便批量处理。
text_list = ["This is great", \
"Thanks for nothing", \
"You've got to work on your face", \
"You're beautiful, never change!"]
classifier(text_list)
# output -> [{'label': 'POSITIVE', 'score': 0.9998785257339478},
# {'label': 'POSITIVE', 'score': 0.9680058360099792},
# {'label': 'NEGATIVE', 'score': 0.8776106238365173},
# {'label': 'POSITIVE', 'score': 0.9998120665550232}]
然而,Hugging Face上的文本分类模型并不仅限于正面-负面情感。例如,SamLowe的“roberta-base-go_emotions”模型生成了一套类标签。我们可以很容易地将此模型应用于文本,如下面的代码片段所示。
classifier = pipeline(task="text-classification", \
model="SamLowe/roberta-base-go_emotions", top_k=None)
classifier(text_list[0])
# output -> [[{'label': 'admiration', 'score': 0.9526104927062988},
# {'label': 'approval', 'score': 0.03047208860516548},
# {'label': 'neutral', 'score': 0.015236231498420238},
# {'label': 'excitement', 'score': 0.006063772831112146},
# {'label': 'gratitude', 'score': 0.005296189337968826},
# {'label': 'joy', 'score': 0.004475208930671215},
# ... and many more
Summarization
pipeline()函数的另一种用途是用于文本摘要。虽然这与情感分析完全不同,但语法几乎相同。
我们首先加载一个摘要模型,然后传入一些文本以及几个输入参数。
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
text = """
Hugging Face is an AI company that has become a major hub for open-source machine learning.
Their platform has 3 major elements which allow users to access and share machine learning resources.
First, is their rapidly growing repository of pre-trained open-source machine learning models for things such as natural language processing (NLP), computer vision, and more.
Second, is their library of datasets for training machine learning models for almost any task.
Third, and finally, is Spaces which is a collection of open-source ML apps.
The power of these resources is that they are community generated, which leverages all the benefits of open source i.e. cost-free, wide diversity of tools, high quality resources, and rapid pace of innovation.
While these make building powerful ML projects more accessible than before, there is another key element of the Hugging Face ecosystem—their Transformers library.
"""
summarized_text = summarizer(text, min_length=5, max_length=140)[0]['summary_text']
print(summarized_text)
# output -> 'Hugging Face is an AI company that has become a major hub for
# open-source machine learning. They have 3 major elements which allow users
# to access and share machine learning resources.'
对于更复杂的用例,可能需要连续使用多个模型。例如,我们可以对摘要文本进行情感分析以加快运行时间。
classifier(summarized_text)
# output -> [[{'label': 'neutral', 'score': 0.9101783633232117},
# {'label': 'approval', 'score': 0.08781372010707855},
# {'label': 'realization', 'score': 0.023256294429302216},
# {'label': 'annoyance', 'score': 0.006623792927712202},
# {'label': 'admiration', 'score': 0.004981081001460552},
# {'label': 'disapproval', 'score': 0.004730119835585356},
# {'label': 'optimism', 'score': 0.0033590723760426044},
# ... and many more
Conversational
最后,我们可以使用专门开发的模型来生成对话文本。由于对话需要将之前的提示和回应传递给后续的模型回应,因此这里的语法有些不同。然而,我们首先使用 pipeline() 函数实例化我们的模型。
chatbot = pipeline(model="facebook/blenderbot-400M-distill")
接下来,我们可以使用Conversation()类来处理这种来回交流。我们用用户提示来初始化它,然后将其传递给前一个代码块的聊天机器人模型。
transformers import Conversation
conversation = Conversation("Hi I'm Shaw, how are you?")
conversation = chatbot(conversation)
print(conversation)
# output -> Conversation id: 9248ee7d-2a58-4355-9fba-525189fae206
# user >> Hi I'm Shaw, how are you?
# bot >> I'm doing well. How are you doing this evening? I just got home from work.
为了使对话持续下去,我们可以使用add_user_input()方法在对话中添加另一个提示。然后,我们将对话对象传递回聊天机器人。
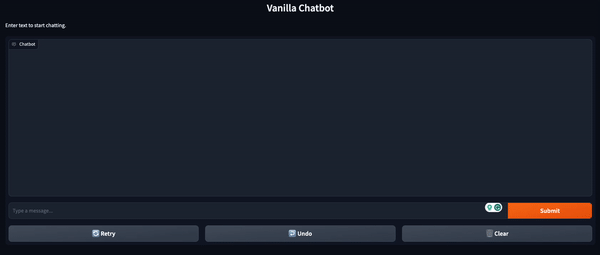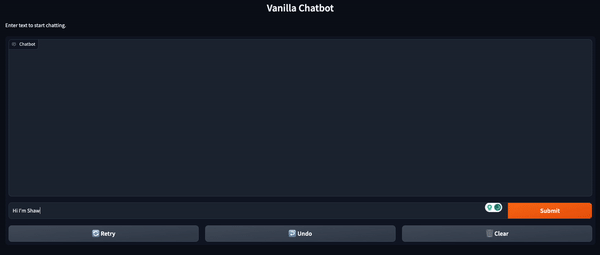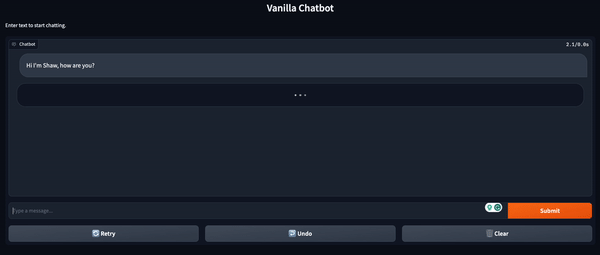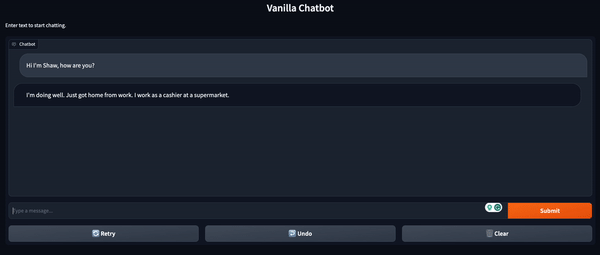
Chatbot UI with Gradio
虽然我们可以使用Transformer库获得基本的聊天机器人功能,但这种方式与聊天机器人的交互并不方便。为了使交互更加直观,我们可以使用Gradio来在几行Python代码中创建一个前端界面。
下面的代码实现了这一功能。首先,我们初始化两个列表,分别用于存储用户的消息和模型的响应。然后,我们定义一个函数,该函数将接受用户的提示并生成聊天机器人的输出。接下来,我们使用Gradio的ChatInterface()类创建聊天界面。最后,我们启动应用程序。
message_list = []
response_list = []
def vanilla_chatbot(message, history):
conversation = Conversation(text=message, past_user_inputs=message_list, generated_responses=response_list)
conversation = chatbot(conversation)
return conversation.generated_responses[-1]
demo_chatbot = gr.ChatInterface(vanilla_chatbot, title="Vanilla Chatbot", description="Enter text to start chatting.")
demo_chatbot.launch()
这将通过本地 URL 启动界面。如果窗口没有自动打开,您可以将 URL 直接复制粘贴到浏览器中打开。
Hugging Face Spaces
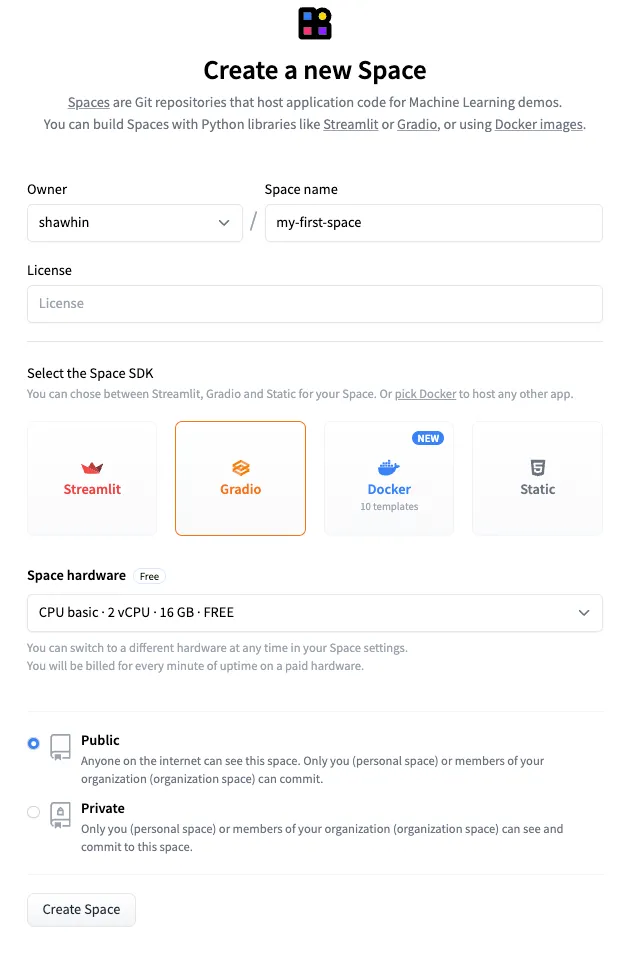
为了进一步,我们可以通过 Hugging Face Spaces 快速部署这个界面。Spaces 是由 Hugging Face 托管的 Git 仓库,并提供计算资源增强。根据使用情况,可以选择免费和付费选项。在这里,我们将使用免费选项。 要创建一个新的 Space,首先打开 Spaces 页面,然后点击 “Create new space”。接下来,配置 Space,给它一个名称,例如 “my-first-space”,并选择 Gradio 作为 SDK。然后点击 “Create Space”。
接下来,我们需要将 app.py 和 requirements.txt 文件上传到 Space 中。app.py 文件包含了我们用于生成 Gradio UI 的代码,requirements.txt 文件则指定了应用程序的依赖项。这个示例的文件可在 GitHub 存储库和 Hugging Face Space 上找到。
最后,我们将代码推送到 Space,就像将代码推送到 GitHub 一样。最终的结果是一个托管在 Hugging Face Spaces 上的公开应用程序。
应用链接:https://huggingface.co/spaces/shawhin/my-first-space
Conclusion
Hugging Face 已经成为开源语言模型和机器学习的代名词。他们的生态系统最大的优势是让小型开发者、研究人员和爱好者能够获得强大的机器学习资源。
虽然在这篇文章中我们涵盖了很多内容,但我们只是触及到了 Hugging Face 生态系统的皮毛。在未来的系列文章中,我们将探讨更高级的用例,并介绍如何使用 🤗Transformers 进行模型微调。
该平台提供了许多强大的工具和资源,使得使用预训练模型变得更加容易,并且为自然语言处理(NLP)和其他机器学习任务提供了很多便利。
期待您在未来的探索中对 Hugging Face 生态系统有更深入的了解。如果您有任何进一步的问题,请随时提问。我随时准备为您提供帮助。
文档信息
- 本文作者:王翊仰
- 本文链接:https://www.wangyiyang.cc/2023/11/04/cracking-open-the-hugging-face-transformers-library/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)