大家好!今天我要和大家聊聊一个在 AI 圈子里引起不小轰动的事件——DeepSeek 的开源周活动。就在 2025 年 2 月 23 日到 27 日,DeepSeek 连续五天,每天开源一个代码仓库,分别是 FlashMLA、DeepEP、DeepGEMM、3FS 和 Smallpond。这五个项目不仅展示了 DeepSeek 在 AI 基础设施领域的深厚技术积累,还为全球 AI 开发者提供了一个难得的合作和创新机会。让我们一起来看看这次开源周到底带来了什么惊喜!
五大开源项目:解锁 AI 基础设施的硬核技术
FlashMLA:GPU 解码的“速度之王”
- 功能:FlashMLA 是一个高效的 MLA(Multi-Head Latent Attention)解码内核,专为 Hopper GPU 设计,支持 BF16 和 FP16 精度。
- 性能:在 H800 SXM5 上,它实现了 3000 GB/s 的内存绑定带宽和 580 TFLOPS 的计算性能。
- 意义:FlashMLA 让 AI 模型在处理变长序列时的推理速度大幅提升,是 GPU 优化的教科书级案例。
DeepEP:MoE 模型的“通信大脑”
- 功能:DeepEP 是全球首个开源的 MoE(Mixture of Experts)模型通信库,支持 NVLink 和 RDMA 通信技术。
- 性能:它优化了 MoE 模型训练和推理中的全对全通信瓶颈,提升了分布式计算效率。
- 意义:MoE 模型因高效处理大规模任务而备受关注,DeepEP 的开源填补了通信工具的空白。
DeepGEMM:FP8 计算的“性能怪兽”
- 功能:DeepGEMM 是一个 FP8 精度的 GEMM(通用矩阵乘法)库,支持密集矩阵和 MoE GEMM 计算。
- 性能:性能高达 1350+ FP8 TFLOPS,核心代码仅约 300 行,简洁却强大。
- 意义:为 DeepSeek 的 V3 和 R1 模型提供支持,展示了低精度计算的高效潜力。
3FS:AI 数据存储的“高速公路”
- 功能:3FS 是一个高性能分布式文件系统,专为 AI 工作负载设计,基于现代 SSD 和 RDMA 网络。
- 性能:聚合读吞吐量高达 6.6 TiB/s,数据访问效率惊人。
- 意义:为大规模 AI 训练提供快速可靠的数据支持,堪称数据处理的“幕后英雄”。
Smallpond:数据处理的“效率助手”
- 功能:Smallpond 是一个数据处理框架,专注优化 AI 模型的数据准备和预处理流程。
- 性能:具体数据尚未公开,但目标是提升数据管道效率。
- 意义:帮助开发者优化模型训练的输入环节,简化复杂的数据工作流。
技术亮点:DeepSeek 的创新密码
GPU 优化的极致追求
FlashMLA 和 DeepGEMM 是 DeepSeek 在 GPU 优化上的代表作。FlashMLA 通过深度适配 Hopper GPU,带来超高解码速度;DeepGEMM 则在 FP8 精度下实现了矩阵运算的性能巅峰。这些技术为 AI 计算提供了强有力的支持。
MoE 架构的突破
MoE 模型因其高效性和灵活性成为 AI 研究的热点。DeepEP 通过优化通信效率,让 MoE 模型的分布式训练和推理更加顺畅,为这一架构的普及铺平了道路。
数据处理的效率革命
3FS 和 Smallpond 则从数据端发力。3FS 提供超高速分布式文件系统,Smallpond 优化数据预处理流程,二者共同构建了高效的 AI 数据管道。
关键要点
- 研究表明,DeepSeek 的五天开源周可能揭示其 AI 开发的技术细节,特别是优化 GPU 性能和 Mixture-of-Experts(MoE)模型的通信库。
- 证据倾向于认为,我们可以发现 DeepSeek 专注于高效的推理内核、矩阵运算库和分布式文件系统,这些可能降低了 AI 训练成本。
- 似乎有可能,DeepSeek 的开源策略将促进 AI 社区的协作。
DeepSeek 的技术方法
DeepSeek-R1 是基于 DeepSeek-V3 开发的,后者在 14.8 万亿个高质量、多样化标记上预训练。DeepSeek 的创新在于其训练方法,特别是使用强化学习(RL)来增强推理能力,而非依赖传统的监督微调(SFT)。根据其研究论文(DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning),他们首先开发了 DeepSeek-R1-Zero,通过纯 RL 训练,展示了显著的推理能力,但存在可读性和语言混合问题。为解决这些问题,他们引入了 DeepSeek-R1,结合多阶段训练和冷启动数据,进一步提升性能。
这种方法表明,RL 可以帮助 LLM 在没有大量标记数据的情况下发展推理能力,这与传统依赖 SFT 的方法形成对比。论文还提到,DeepSeek-R1 在数学、代码和推理任务上的表现可与 OpenAI 的 o1 模型媲美。
成本效率与争议
DeepSeek 声称其训练成本远低于竞争对手。例如,DeepSeek-V3 的训练成本据称仅为 600 万美元,而 OpenAI 的 GPT-4 据称成本高达 1 亿美元,Meta 的 Llama 3.1 也需要更多计算能力(DeepSeek – Wikipedia)。然而,这一成本主张存在争议。一些分析(如 Martin Vechev of INSAIT: “DeepSeek $6M Cost Of Training Is Misleading”)指出,600 万美元可能仅包括计算成本,不包括薪资、数据注释和失败训练的费用。另有报道估计,DeepSeek 的硬件支出可能高达 5 亿美元(DeepSeek’s hardware spend could be as high as $500 million, new report estimates)。
尽管如此,DeepSeek 的成本效率挑战了 AI 开发需要巨额硬件投资的传统观念。他们的 API 定价也反映了这一趋势,例如 DeepSeek-R1 的输入标记成本为每百万 0.14 美元(缓存命中),远低于 OpenAI 的 o1 模型(A Simple Guide to DeepSeek R1: Architecture, Training, Local Deployment, and Hardware Requirements)。
开放源代码策略
DeepSeek 使其模型开源,这对 AI 社区意义重大。DeepSeek-R1 和其变体(如 DeepSeek-R1-Zero)在 MIT 许可下发布,允许任何人下载、复制和构建(DeepSeek-R1 Release | DeepSeek API Docs)。这与 OpenAI 和 Anthropic 等公司保密模型形成对比,也与 Meta 和 Google 的部分开源模型不同,后者的使用受许可限制(What is open-source AI and how could DeepSeek change the industry?)。
开源策略促进了 AI 社区的协作和创新。例如,已经发布的基于 Llama 和 Qwen 的六个小型模型(1.5B 至 70B 参数),这些模型可以通过普通消费级笔记本电脑运行(DeepSeek R1 vs OpenAI o1: Installation, Features, Pricing)。这降低了 AI 开发的进入壁垒,特别是对中小企业和个人开发者。
全球影响与未来展望
DeepSeek 的成功在全球 AI 格局中引发了讨论。一些评论家将其称为“AI 的斯普特尼克时刻”,表明中国在 AI 开发中的快速进步可能挑战美国的主导地位(What is DeepSeek – and why is everyone talking about it?)。这也引发了关于美国出口控制是否有效的讨论,因为 DeepSeek 声称其模型在硬件限制下仍能取得成功(What DeepSeek r1 Means—and What It Doesn’t)。
未来,DeepSeek 的方法可能推动更多采用 RL 技术,降低训练成本,并促进开源运动。这也可能影响 AI 开发的可持续性,因为较低的计算需求可能减少能源消耗。此外,DeepSeek 的创始人梁文锋在采访中强调,中国 AI 行业不应永远追随,而应领导创新(Interview with Deepseek Founder: We’re Done Following. It’s Time to Lead.),这可能激励其他公司采用类似策略。
OpenSourceWeek 的详细分析
DeepSeek 的 OpenSourceWeek 从 2025 年 2 月 23 日开始,持续五天,每天发布一个代码仓库。以下是每个仓库的详细描述:
| Day | Tool/Library | Description | URL | Key Features/Performance |
|---|---|---|---|---|
| 1 | FlashMLA | Efficient MLA Decoding Kernel for Hopper GPUs | https://github.com/deepseek-ai/FlashMLA | BF16 support, Paged KV cache (block size 64), 3000 GB/s memory-bound, BF16 580 TFLOPS on H800 |
| 2 | DeepEP | First open-source EP communication library for MoE model training/inference | https://github.com/deepseek-ai/DeepEP | Efficient all-to-all communication, intranode/internode support with NVLink/RDMA, FP8 dispatch |
| 3 | DeepGEMM | FP8 GEMM library for dense and MoE GEMMs, powering V3/R1 training/inference | https://github.com/deepseek-ai/DeepGEMM | Up to 1350+ FP8 TFLOPS on Hopper GPUs, ~300 lines core logic, JIT compiled |
| 4 | DualPipe, EPLB, Profile Data | Optimized parallelism strategies for V3/R1 | https://github.com/deepseek-ai/DualPipe, https://github.com/deepseek-ai/EPLB, https://github.com/deepseek-ai/profile-data | DualPipe: bidirectional pipeline parallelism, EPLB: expert-parallel load balancer, profile data analysis |
| 5 | 3FS, Smallpond | Fire-Flyer File System (3FS) and data processing framework Smallpond | https://github.com/deepseek-ai/3FS, https://github.com/deepseek-ai/smallpond | 3FS: 6.6 TiB/s aggregate read throughput (180-node), 3.66 TiB/min GraySort (25-node), 40+ GiB/s per client for KVCache |
每个仓库的详细功能
- FlashMLA:FlashMLA 是一个高效的 MLA 解码内核,优化 Hopper GPU,适用于变长序列服务。它支持 BF16 和 FP16,使用 paged kvcache(块大小 64),在 H800 SXM5 上达到 3000 GB/s(内存绑定配置)和 580 TFLOPS(计算绑定配置),使用 CUDA 12.8(deepseek-ai/FlashMLA)。
- DeepEP:DeepEP 是第一个开源 EP 通信库,用于 MoE 模型训练和推理。它提供高效的全对全通信,支持 intranode 和 internode 操作,使用 NVLink 和 RDMA,优化 FP8 分派(deepseek-ai/DeepEP)。
- DeepGEMM:DeepGEMM 是一个 FP8 GEMM 库,支持密集和 MoE GEMM,训练和推理 V3/R1 模型。它在 Hopper GPU 上达到 1350+ FP8 TFLOPS,核心逻辑约 300 行,完全 JIT 编译,无重依赖(deepseek-ai/DeepGEMM)。
- 3FS:3FS(Fire-Flyer File System)是一个高性能分布式文件系统,设计用于 AI 训练和推理工作负载。它利用现代 SSD 和 RDMA 网络,提供共享存储层,简化分布式应用开发。性能亮点包括:
- 峰值吞吐量:6.6 TiB/s(180 节点集群,每个节点 2×200Gbps InfiniBand NIC 和十六个 14TiB NVMe SSD)。
- GraySort 基准测试:8,192 分区 110.5 TiB 在 30 分 14 秒内排序,达到 3.66 TiB/min(25 节点集群)。
- KVCache:每个客户端峰值读取吞吐量高达 40 GiB/s(deepseek-ai/3FS)。
- Smallpond:Smallpond 是一个数据处理框架,可能用于 AI 模型的数据准备和预处理。尽管具体细节有限,但其开源表明 DeepSeek 愿意分享其数据管道的细节(deepseek-ai/smallpond)。
发现与洞察
通过这些发布,我们可以发现 DeepSeek 在以下方面的重点:
- GPU 优化:DeepSeek 对 Hopper GPU 的优化表明他们正在利用最新 GPU 技术以实现高性能。FlashMLA 和 DeepGEMM 展示了他们在推理和矩阵运算方面的努力。
- MoE 架构:DeepEP 和 DeepGEMM 的存在表明 DeepSeek 专注于 Mixture-of-Experts 模型,这在处理大规模数据和复杂任务时效率更高。
- 自定义 AI 基础设施:3FS 和 Smallpond 揭示了 DeepSeek 开发定制存储和数据处理解决方案的能力,这可能降低训练成本并提高效率。
- 开源承诺:开放这些关键组件表明 DeepSeek 致力于与社区合作,促进 AI 创新,但也引发了关于国家安全和知识产权的讨论。例如,一些分析家担心开源模型可能被滥用(What is open-source AI and how could DeepSeek change the industry?)。
- 成本效率:DeepSeek 的高效库和定制硬件解决方案可能有助于降低训练和部署模型的成本,这与其声称的低成本训练(如 DeepSeek-V3 600 万美元)相符,但这一主张存在争议(Martin Vechev of INSAIT: “DeepSeek $6M Cost Of Training Is Misleading”)。
全球影响与未来展望
DeepSeek 的成功可能改变 AI 开发的未来,包括更多采用 RL 技术、降低训练成本和促进开源运动。这也可能影响全球 AI 格局,特别是在中美 AI 竞争中。例如,DeepSeek 的低成本模型可能挑战美国公司在 AI 领域的估值,导致股市波动(如 2025 年 1 月 27 日 Nasdaq 下跌 3.1%)(How the buzz around Chinese AI model DeepSeek sparked a massive Nasdaq sell-off)。
此外,DeepSeek 的开源策略可能激励其他公司采用类似策略,促进 AI 的民主化和可持续性。梁文锋强调,中国 AI 行业不应永远追随,而应领导创新,这可能激励全球 AI 社区(Interview with Deepseek Founder: We’re Done Following. It’s Time to Lead.)。
详细数据与分析
以下是 DeepSeek-R1 的一些关键性能指标,摘自其研究论文和相关报道:
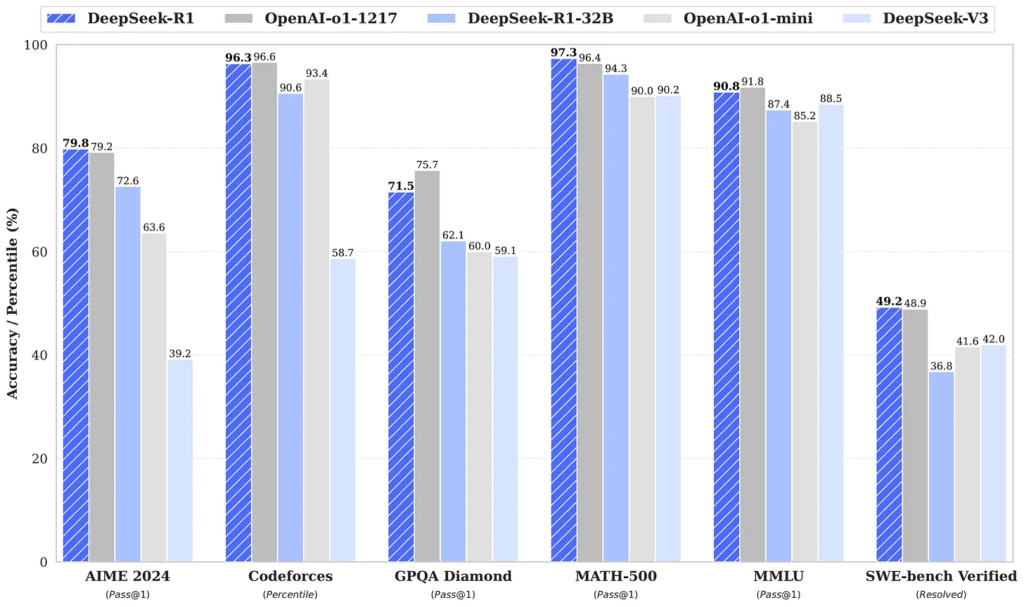
这些数据表明,DeepSeek-R1 在多个推理任务上与 o1 相当,但其运行成本低得多,输入标记成本为 o1 的 1/27(DeepSeek Releases R1 and Opens up AI Reasoning)。
结论
通过 DeepSeek 的五天开源周,我们可以发现其创新的 GPU 优化方法、MoE 模型支持和定制 AI 基础设施。这些发现不仅揭示了 AI 开发的潜在新方向,也可能改变全球 AI 格局。未来,DeepSeek 的成功可能激励更多公司采用类似策略,促进 AI 的民主化和可持续性。