引言
想象你有一份长达百页的 PDF 工作报告,需要快速找到特定信息,翻页查找太费时了。如果能直接问问题,PDF 就能回答你呢?这就是 ChatPDF 的作用——它就像一个懂你的个人助理,能通过自然语言与 PDF 互动。
本文将教你如何用 LangChain 和 Gradio 打造自己的 ChatPDF 应用。LangChain 是一个强大的框架,帮助开发基于大语言模型(LLM)的应用,而 Gradio 则提供简单易用的网页界面。结合起来,你就能创建一个工具,让你像聊天一样与 PDF 互动。
这是我们系列文章的延续,之前已发布过 LangChain 基础、智能汽车推荐系统等内容。如果你对这些技术感兴趣,不妨回顾之前的文章。本文将一步步带你实现 ChatPDF,适合技术爱好者和开发者。
项目架构
构建 ChatPDF 包括以下关键步骤:
- PDF 文件处理:提取 PDF 文本,让 AI 能理解内容。
- 文本分块与索引:将文本拆分成小块并创建索引,方便快速搜索。
- 自然语言查询:通过 AI 解读用户问题,并基于 PDF 内容生成答案。
- 对话管理:支持多轮对话,保持上下文。
- 用户界面:用 Gradio 打造简单网页界面,方便上传 PDF 和提问。
这些步骤结合 AI 和机器学习技术,确保 ChatPDF 高效实用。
实现步骤详解
以下是优化后的实现步骤,代码已更新为使用 OpenAI 的模型和嵌入,适合微信阅读。
1. 安装依赖
首先安装必要的库:
pip install -U langchain pypdf faiss-cpu openai gradio langchain-community langchain_openai python-dotenv
这些库包括 LangChain(处理链式调用)、PyPDF(PDF 处理)、FAISS(向量索引)和 Gradio(网页界面)。
2. 加载与处理 PDF
用 LangChain 的 PyPDFLoader 加载 PDF 并分块:
from langchain_community.document_loaders import PyPDFLoader
def load_pdf(file_path):
loader = PyPDFLoader(file_path)
documents = loader.load_and_split()
return documents
PyPDFLoader 是一个工具,帮助从 PDF 文件中提取文本并拆分成小块,方便 AI 处理。
3. 构建文本索引
用 OpenAI 的嵌入模型生成向量,并用 FAISS 存储,加速搜索:
from langchain.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from dotenv import load_dotenv
import os
load_dotenv()
def create_index(documents):
embeddings = OpenAIEmbeddings(
openai_api_key=os.getenv("OPENAI_API_KEY"),
)
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store
嵌入(Embeddings)是将文本转为数字向量,方便比较和搜索。OpenAI 的嵌入模型(如 text-embedding-ada-002)通用性强,但对非英语文本性能可能稍弱。
4. 构建自然语言查询链
用 RetrievalQA 结合 OpenAI 的模型生成答案:
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
def create_qa_chain(vector_store):
llm = ChatOpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
model_name="gpt-3.5-turbo",
)
qa_chain = RetrievalQA.from_chain_type(llm, chain_type="stuff", retriever=vector_store.as_retriever())
return qa_chain
RetrievalQA 先检索相关文档,再用 AI 模型(如 gpt-3.5-turbo)生成答案,确保准确性。
注意:本文使用 OpenAI 的 gpt-3.5-turbo,主要针对英语文本。对于中文 PDF,建议考虑支持中文的模型,调整参数以提升性能。
5. 使用 Gradio 构建界面
用 Gradio 创建网页界面,方便用户上传 PDF 并提问:
import gradio as gr
def chat_with_pdf(pdf, question):
documents = load_pdf(pdf.name)
vector_store = create_index(documents)
qa_chain = create_qa_chain(vector_store)
answer = qa_chain.run(question)
return answer
pdf_input = gr.File(label="上传 PDF 文件")
question_input = gr.Textbox(label="输入问题")
output = gr.Textbox(label="答案")
gr.Interface(fn=chat_with_pdf, inputs=[pdf_input, question_input], outputs=output).launch(server_name="0.0.0.0", server_port=7860)
运行后,用户可通过浏览器上传 PDF,输入问题,系统会返回答案。
运行与测试
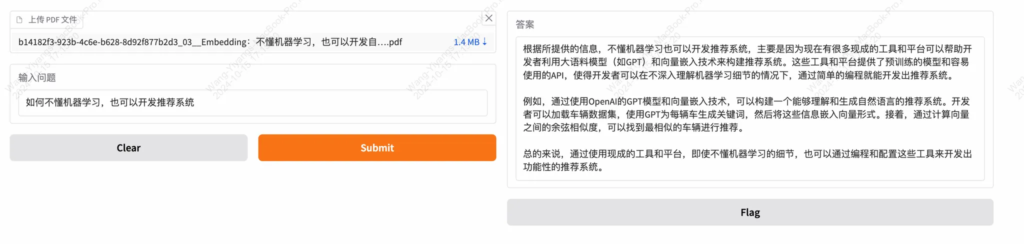
运行代码后,Gradio 会启动本地服务。例如,上传一份技术文档,问“这份文档的主要内容是什么?”,ChatPDF 会从文档中提取答案并返回。
互动示例
使用 ChatPDF 的步骤如下:
- 上传 PDF:点击“上传 PDF 文件”按钮,选择你的文档。
- 提问:在“输入问题”框中输入,如“这份报告的结论是什么?”。
- 获取答案:系统会在“答案”框中显示结果。
例如,上传一份 Python 编程 PDF,问“列表和元组的区别是什么?”,ChatPDF 会查找相关内容并给出答案。这对学生、专业人士等需要快速提取信息的人非常实用。
总结与展望
通过 LangChain 和 Gradio,我们快速搭建了 ChatPDF 应用,让用户能自然语言与 PDF 互动。核心技术基于 RAG(检索增强生成),通过检索文档片段并结合 OpenAI 模型生成答案,特别适合处理大型文档。
未来可优化支持更多文件格式,或使用更强大的模型提升准确性。对于非英语 PDF,建议关注支持多语言的模型或调整参数。
本文是系列文章的延续,之前已发布 LangChain 基础、智能汽车推荐系统等内容,共同探索 AI 应用的实践。