在上一篇文章中,我们介绍了如何使用 DeepSeek R1 + LangChain 来生成报告。今天,我们将更进一步,探讨如何结合数据分析和可视化,让 AI 帮我们生成一份包含图表的专业数据分析报告 PPT。
本文源码已上传至:GitHub
LangChain Agent 简介
在深入代码实现之前,我们先来了解一下 LangChain Agent 的核心概念和工作原理。
什么是 LangChain Agent?
LangChain Agent 是一个智能代理系统,它能够:
- 理解用户的自然语言指令
- 规划完成任务所需的步骤
- 调用适当的工具来执行这些步骤
- 整合各个步骤的结果
简单来说,Agent 就像是一个智能助手,它知道如何组合使用各种工具来完成复杂任务。
Agent 的工作流程
- 输入解析:Agent 接收用户的自然语言指令
- 任务规划:分析需要完成的任务,并制定执行计划
- 工具选择:从可用的工具集中选择合适的工具
- 执行操作:按照计划调用工具,执行具体操作
- 结果整合:将各个步骤的结果组合成最终输出
Agent 的核心组件
- LLM(大语言模型)
- 负责理解用户指令
- 生成执行计划
- 决策下一步行动
- Tools(工具)
- 具体功能的实现
- 通过装饰器注册
- 提供标准化接口
- Memory(记忆)
- 存储对话历史
- 维护状态信息
- 支持上下文理解
- Agent类型
- ZERO_SHOT:直接根据工具描述选择工具
- REACT:使用思维链进行推理
- PLAN_AND_EXECUTE:先规划再执行
- 等等
主要功能概述
我们将实现以下核心功能:
- 数据可视化:支持生成多种类型的图表(柱状图、折线图、饼图、散点图)
- 文件处理:支持读取多种格式的数据文件(CSV、Excel、Word、网页)
- PPT 生成:支持多种幻灯片布局(标题页、纯文本页、图文混排页)
- AI 驱动:使用 LangChain 框架实现智能化的内容生成和排版
整体流程图如下:
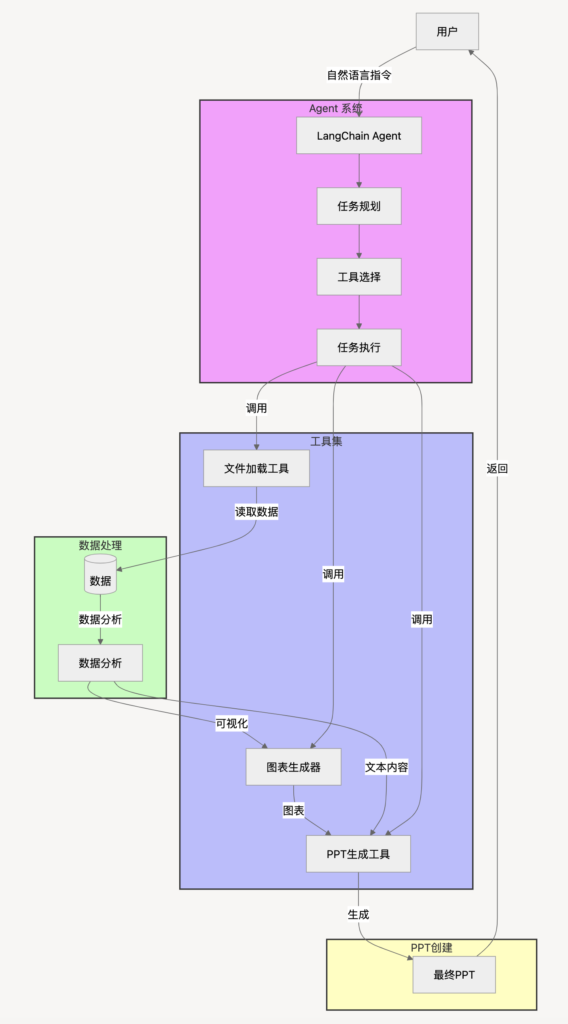
 引言:DeepSeek R1 的数据分析革命
引言:DeepSeek R1 的数据分析革命 卓越性能指标
卓越性能指标 一、开发环境准备
一、开发环境准备 二、核心实现(30行代码)
二、核心实现(30行代码)